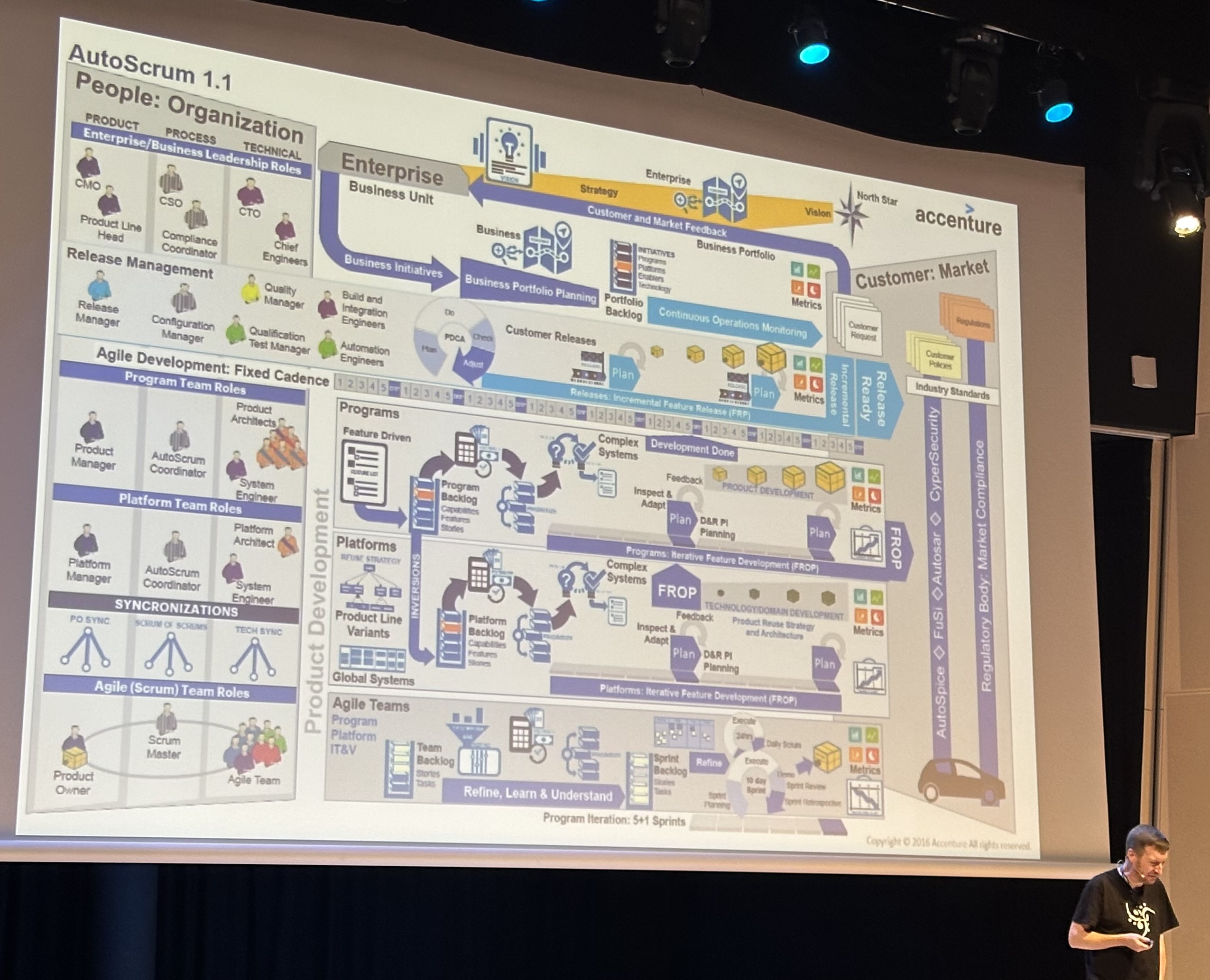
The first thing I just have to mention is the food here on Devoxx Ma. It is awesome!! Wow the best food I’ve ever had one any conference ever.
Day 1 - October 11
to the left
Security
Too bad he had problems with connection to internet and the workshop went way to fast but the talk had potential
Because Sonatype hosts the complete maven central repository they know exactly what is downloaded, so they also know that e.g. the log4j with the enormous bug is still being downloaded a lot!
We need to be much more vigilant with security as developers!!
Portability Paradox
Yeah what can I say? Not too impressed with this talk. Not much attention was given to the demo (it was not working or finished) which was a shame and he went over the material very fast.
The other thing going through my mind is: how many companies actually work cross-cloud?? Not sure but my guess is not many…
dare to test prod on testcontainers
Nice talk! Recreate the complete prod env
serverless application on google cloud
Workshop was nice. Trouble is that none of my clients actually work with google cloud 🌧️
Day 2 - October 12
keynote
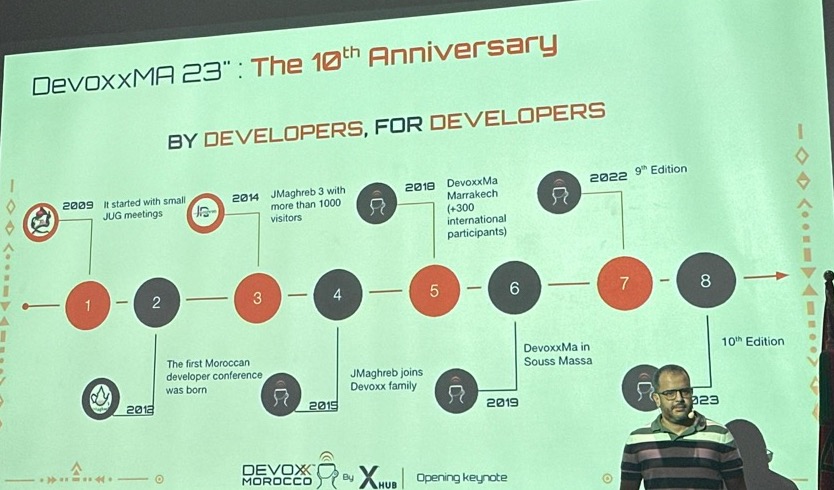
This is the 10th edition of DevoxxMA.
We held a minute of silence for the victims of the earthquake.
DevoxxMA broke the record this year in the number of CFP they received and they had to be really selective.
The minister of digitalization gave us a video greeting.
A couple of the main sponsors got a few minutes on stage and said some nice words to the crowd in French.
No goody bag and gifts this year because the complete budget of that goes to earthquake rebuilding.
Devoxx 4 kids … nice!
How software is the key
I did not really want to go to this talk but I could not really leave as most people stayed 😂.
Ha I did leave after a few minutes because many more were leaving.
GraalVM
Live demo’s yeah!! 👍
A design pattern goes to market
Kaya had an awesome talk about some common design patterns!!
The talk had a nice “real life” approach and was really well received!
I liked it a lot. 👍
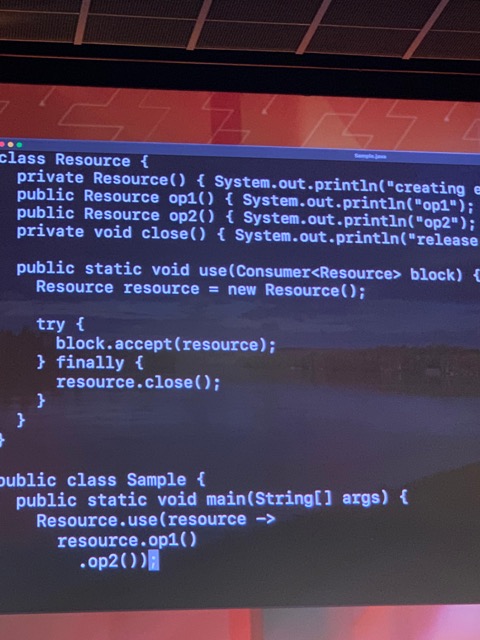
Simplifying concurrency with Project Loom
Day 3 - October 13
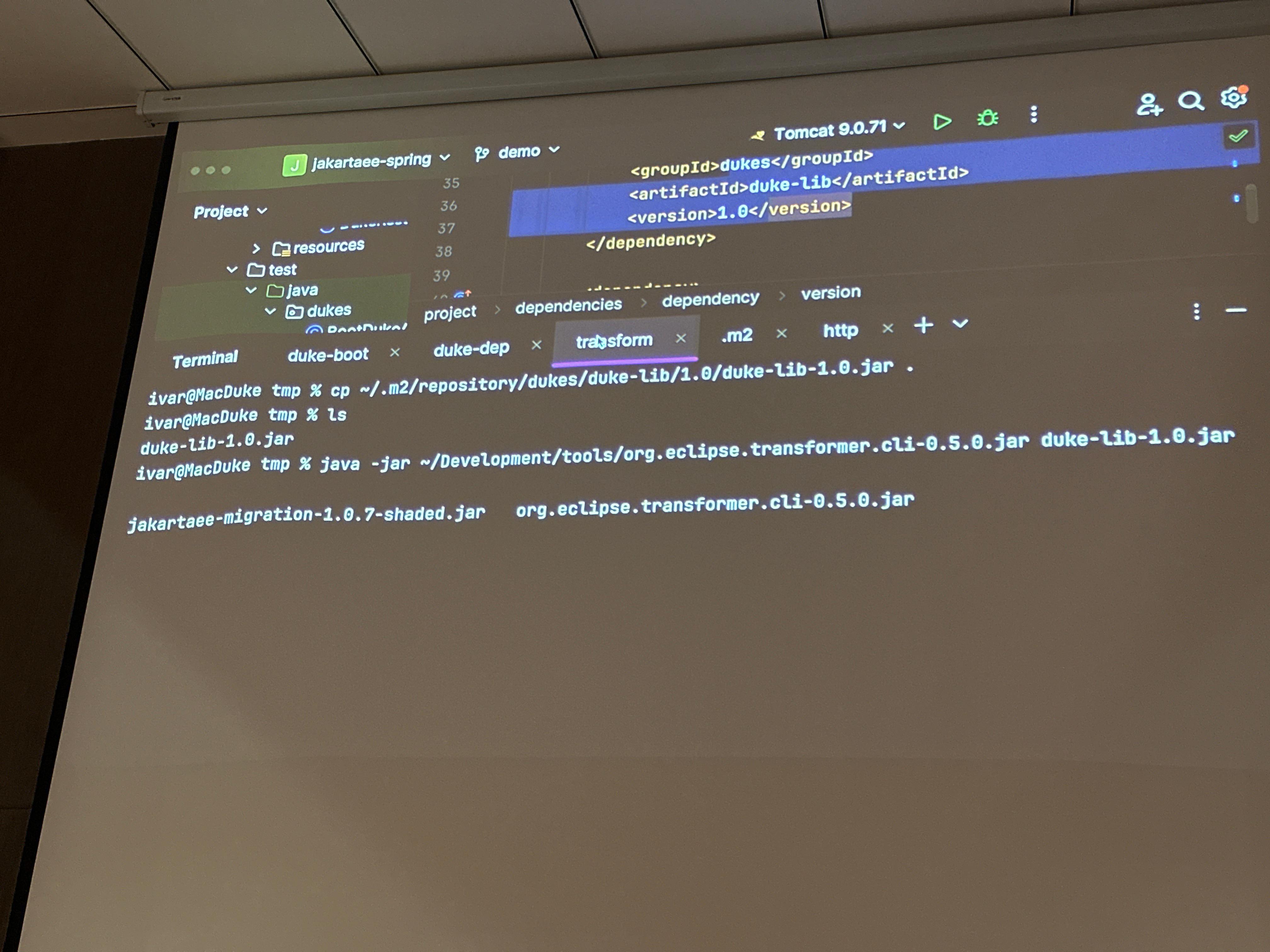
spring-boot 2 to 3 with JakartaEE
Ivar Grimstad has a nice talk about the migration from spring-boot 2 to 3 with JakartaEE.
It was really great hanging out with him at the conference!
Thanks for the beers Ivar! 🍻
aftermath
after lunch it wrapped up and it was time to relax a bit, which was not very difficult :-)
]]>
<h1 id="Devoxx-Marokko-2023"><a href="#Devoxx-Marokko-2023" class="headerlink" title="Devoxx Marokko 2023"></a>Devoxx Marokko 2023</h1><p><img src="/images/2023/Devoxx-Marokko-2023/Devoxx-Marokko-2023_1.jpg" style="width:50%;height:50%;display: block;margin: 0 auto;"></p>
<p>The first thing I just have to mention is the food here on Devoxx Ma. It is awesome!! Wow the best food I’ve ever had one any conference ever. </p>
Springboot 3 Upgradehttp://www.ivonet.nl/2023/08/14/Springboot-3-Upgrade/2023-08-14T07:32:00.000Z2023-10-23T15:43:34.000Zspring-boot 2.x.x to 3.1.2 migration
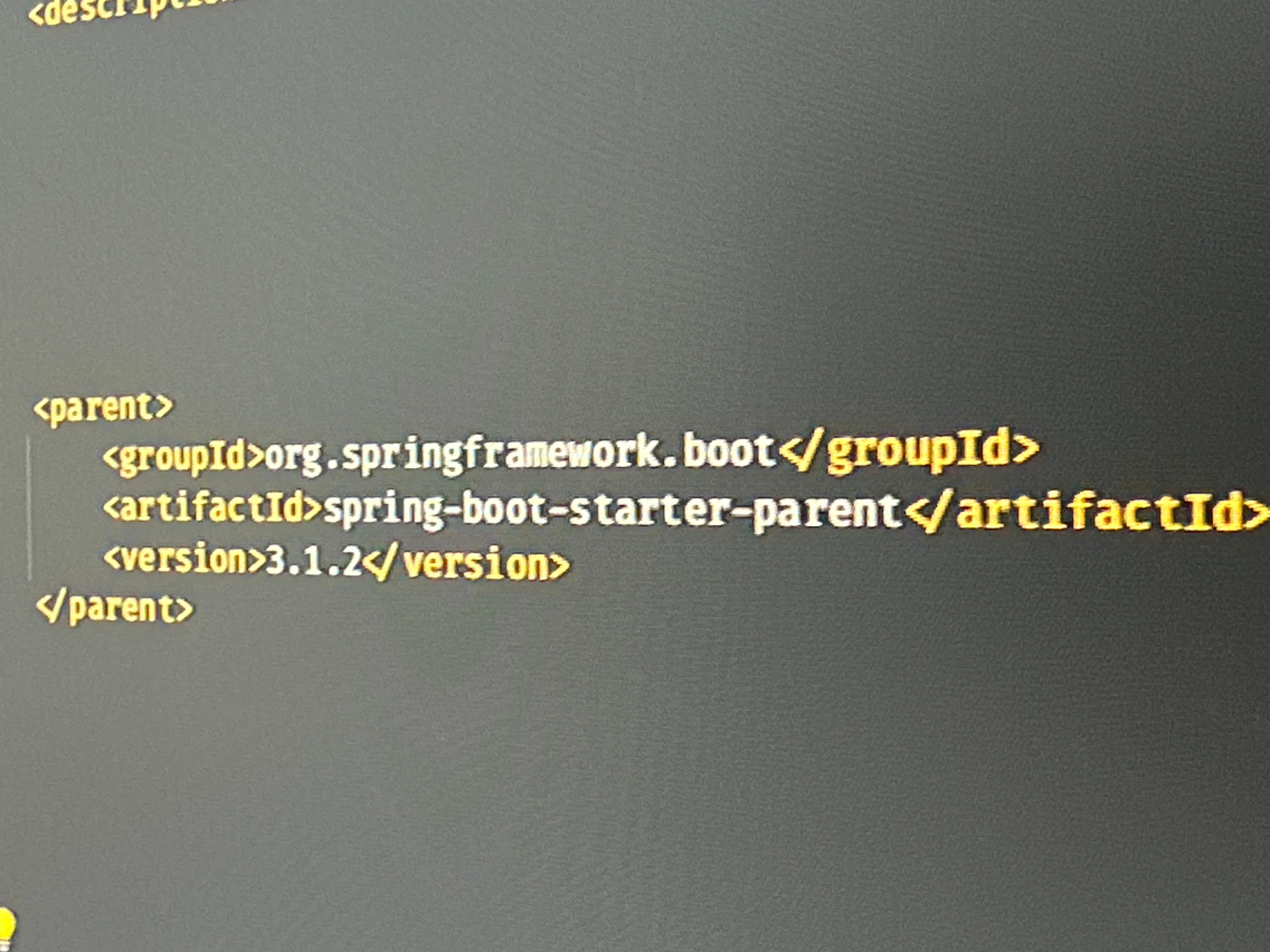
Right now I have to do a couple of spring-boot 2.5.x and 2.7.x upgrades to spring-boot 3.1.2 (current latest). As this is a major version it is not necessarily trivial. Luckily a few very good hot-to’s have already been written, so I will only mention the standard things, but I will also try to write about the other things I encountered during the upgrade and about how I made it work.
Standard things to do
Install and use Java 17+ and make sure the project is using it. In the pom.xml:
Upgrade to the latest version of spring-boot 2 (for me that is 2.7.14) and see if everything still works
Add the following dependency to the pom and build and run the application. In the run output you can find if properties have been changed and solve the problems
In this section I will describe the things I encountered during the upgrade and how I solved them. If a title does not apply to you, just skip it.
your own starter modules
If you have your own starter(s) then it is important to upgrade them first. And it is small but important change!
The META-INF/spring.factories file has changed to META-INF/spring/org.springframework.boot.autoconfigure.AutoConfiguration.imports and the contents is only the fully qualified AutoConfiguration class name or a list of them one per line
The BinderAwareChannelResolver class has been deprecated and removed. It is replaced by the org.springframework.cloud.stream.function.StreamBridge class.
Change the call to the BinderAwareChannelResolver to a call to the StreamBridge class.
BinderAwareChannelResolver to StreamBridge
In the new versions (dependencies) of spring-boot the BinderAwareChannelResolver has been removed. It is replaced by the StreamBridge class.
change the following code in the class using BinderAwareChannelResolver:
if you have HTTP PATCH methods it will probably result in an error like this:
1 2 3 4 5
feign.RetryableException: Invalid HTTP method: PATCH executing PATCH [...] at feign.FeignException.errorExecuting(FeignException.java:277) ~[feign-core-12.4.jar:na] at feign.SynchronousMethodHandler.executeAndDecode(SynchronousMethodHandler.java:110) ~[feign-core-12.4.jar:na] at feign.SynchronousMethodHandler.invoke(SynchronousMethodHandler.java:70) ~[feign-core-12.4.jar:na] at feign.ReflectiveFeign$FeignInvocationHandler.invoke(ReflectiveFeign.java:96) ~[feign-core-12.4.jar:na]
Add the following to your pom.xml or its equivalent in your build framework:
]]>
<h1 id="spring-boot-2-x-x-to-3-1-2-migration"><a href="#spring-boot-2-x-x-to-3-1-2-migration" class="headerlink" title="spring-boot 2.x.x to 3.1.2 migration"></a>spring-boot 2.x.x to 3.1.2 migration</h1><p><img src="/images/2023/Springboot-3-Upgrade/Springboot-3-Upgrade.jpg" style="width:50%;height:50%;display: block;margin: 0 auto;"></p>
<p>Right now I have to do a couple of spring-boot 2.5.x and 2.7.x upgrades to spring-boot 3.1.2 (current latest).<br>As this is a major version it is not necessarily trivial. Luckily a few very good hot-to’s have already been written,<br>so I will only mention the standard things, but I will also try to write about the other things I encountered during the<br>upgrade and about how I made it work.</p>
Joy Of Coding 2023http://www.ivonet.nl/2023/06/23/Joy-Of-Coding-2023/2023-06-23T08:27:00.000Z2023-06-23T15:41:12.000Z
Programming’s greatest mistakes
Mark Rendle did a great talk about our greatest mistakes.
He gave a lot of examples about mistakes and what they did cost.
Some of the worst mistakes are actually enterprise versions of agile 😂. I soo agree!
😂😂😜
How your brain learns new (programming) languages
repeat
read new stuff aloud
know about the 6 chunks of short term memory
be patient
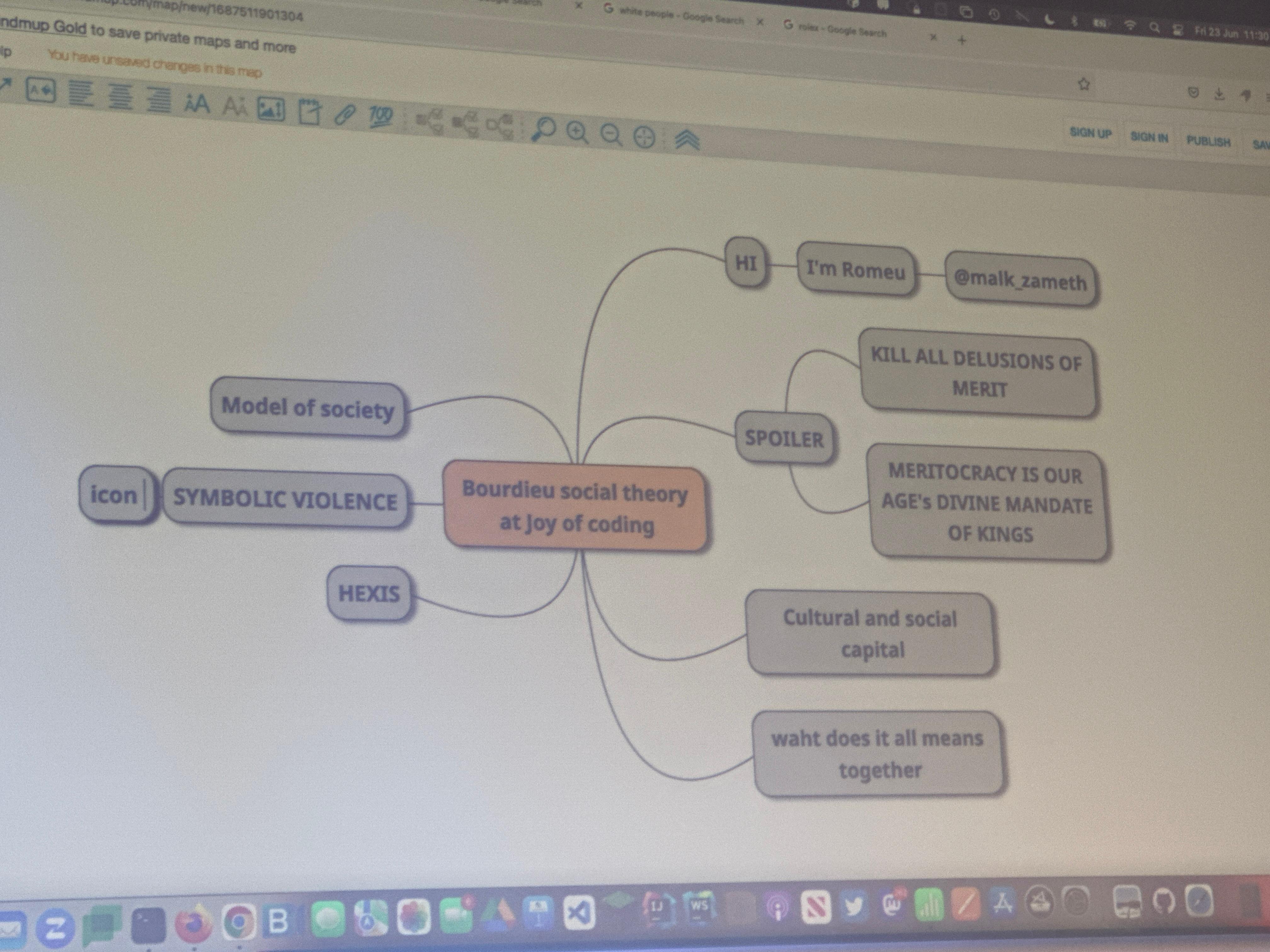
Bourdieu’s social theory applied to tech
Romeu Moura has a great talk about this subject. He engages us and is funny. His use of mindmap as a presentation tool is very nice and dynamic.
The Importance of Fun in the Workplace
Holly Cummins.
ducks make jokes funnier
in the UK the letter K makes jokes funnier
Joy in the workspace feels like something hidden and secret.
If you make people happy. Your business will do well.
play leads to profit
Get rid of estimates! They are mostly wrong so why do it?!
Gamification
Fun is not a formula
lightning talks
Code burnout.
Go Rust!
The Wonder of Open Source
everyone in fashion hates each other
they actively try to sabotage each other or steal each other’s ideas
Open Source is actually the total opposite.
This is actually really special and we should treasure it.
Open Source is actually kind of the standard nowadays.
he thanks us all for that!
sharing knowledge
Making the world a slightly better place
the joy of coding competitions
Bert-Jan Schrijver
Code Golf: in the least amount of chars solve problem.
Advent of code: yeah.
The point is the keep writing code
bee keeping
Mark van Straten
There is an tremendous amount of similarities between bees and tech
He compared bee keeping to software development and he used bee terminology constantly which was fun.
start small
give them autonomy
you will bee amazed at what they can achieve
if you just let them “bee” 😂
Are you testing your unit tests?
Short talk about making sure your tests are actually good
It advocates mutation testing.
Serverless Kotlin in seconds with kotless
It is about kotless Incubator project.
Nice example.
The Ikea Effect
I build it myself gives joy
Sharing is caring. Please look first if someone already wrote it
quizz about…
The public static void main
Very fun quiz with songs by Hanno singing only public static void main!
Fun!
Raw Wasm: Hand-crafted WebAssembly Demos
He demos lots of cool web assembly code.
Cool demos. I don’t want to write in raw we assembly though. 😂😎
How shit works: Databases
By Tober Gabel
The crux is that nowadays the choice of a db is more a question of existing knowledge and not what is precisely needed. All of them are probably good if you already have knowledge.
This does not mean that if you know what your system needs to do a better choice cannot be made.
Do not choose the one thing you have no knowledge about and listen to your OPS person
Expert software developers’ approach to error
Good topic but the presenter read a lot and was boring. Sry.
Conclusion was good though.
Errors are an opportunity to challenge wow, teach, etc and is not a blame game!
Email vs Capitalism: A Story About Why We Can’t Have Nice Things
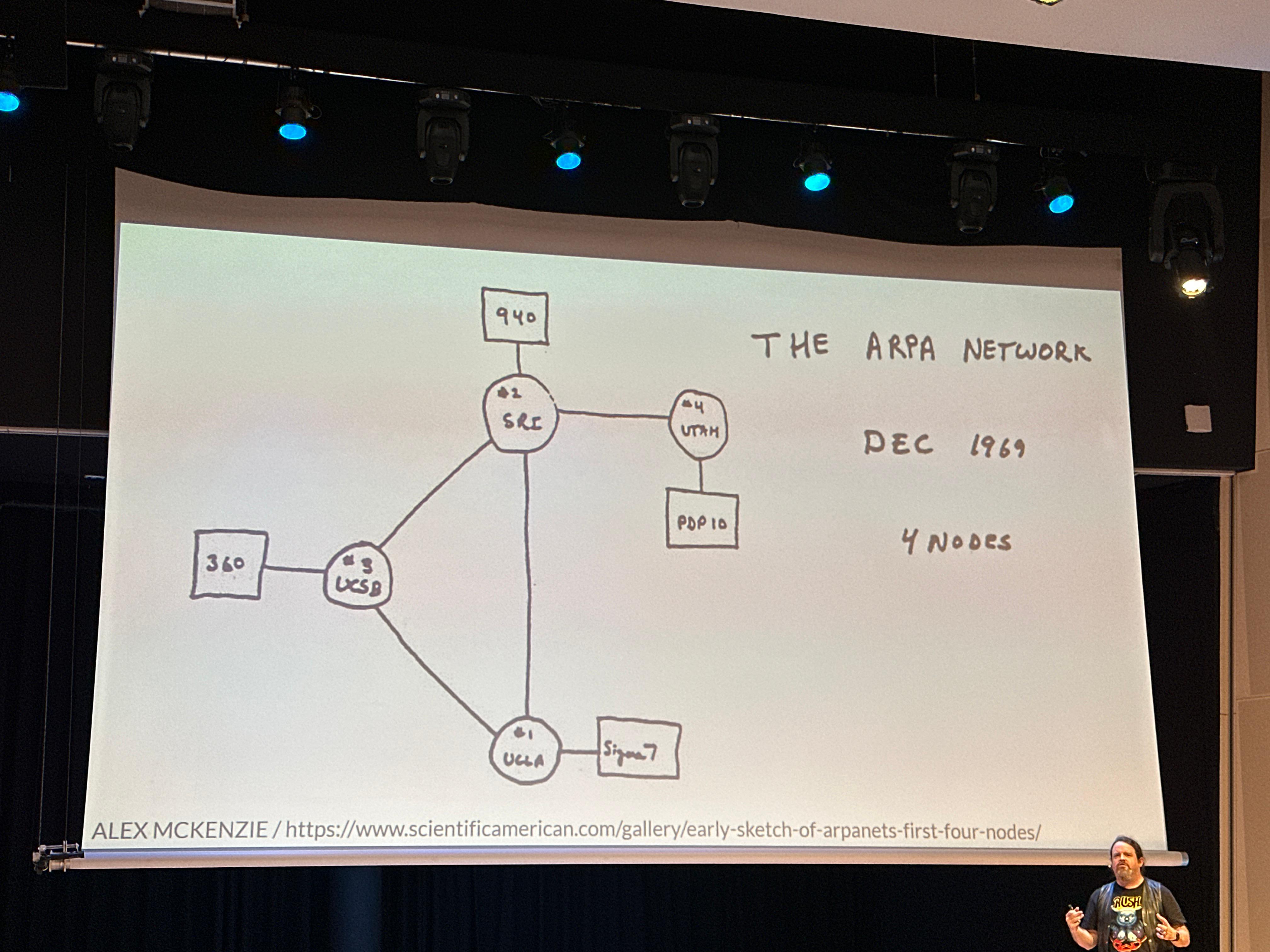
Java SE 20 was released March 21, 2023, so it should be generally available when this article is published.
Most of the JEPs in this release have something to do with Pattern Matching or Virtual Threads and are resubmissions of already known Incubator and Preview features. This version doesn’t contain any new main features. The most exciting innovation in this release is called “Scoped Values” and is intended to widely replace thread-local variables.
In this article we will take a look at all the new and resubmitted Incubator and Preview features.
1 2 3 4
$ docker run -it --rm \ -v $(pwd)/src:/src \ openjdk:20-slim /bin/bash $ cd /src/java20
Listing 1
Preview and Incubator features
429: Scoped Values (Incubator)
Just like Virtual Threads (see below), Scoped Values were developed as part of Project Loom [reference 4].
Project Loom is intended to explore, incubate and deliver Java VM features, and APIs built on top of them for the purpose of supporting easy-to-use, high-throughput lightweight concurrency, and new programming models on the Java platform.
The Scoped Values feature in Java provides a way to define a value within a particular scope and ensures that it is used only within that scope. This feature makes it easier to manage data and reduces the risk of errors by limiting the scope of that data to only the areas where it is needed.
$ java --add-modules jdk.incubator.concurrent --enable-preview --source 20 JEP429.java WARNING: Using incubator modules: jdk.incubator.concurrent Duke Java
Listing 2
432: Record Patterns (Second Preview)
This JEP aims to improve the expressiveness and readability of code that deals with records. A record pattern can be used with instanceof or switch to access the fields of a record without casting and calling accessor methods [listing 3].
Type pattern matching was introduced in Java through JEP 394 in Java SE 17. The switch case statement was enhanced to work with pattern matching in JEP 406 and 420 in Java SE 18 [see also reference 2 and 3 for examples].
publicclassJEP432{ record Pair(Object x, Object y){ } record Point(int x, int y){} enum Color { RED, GREEN, BLUE } record ColoredPoint(Point p, Color c){} record Rectangle(ColoredPoint upperLeft, ColoredPoint lowerRight){} publicstaticvoidnoMatchExample(){ Pair p = new Pair(42, 42); System.out.println("p instanceof Pair(String s, String t) -> " + (p instanceofPair(String s, String t))); } staticvoidprintUpperLeftColors(Rectangle[] r){ for (Rectangle(ColoredPoint(Point p, Color c), ColoredPoint lr): r) { System.out.println(c); } } staticvoiddump(Point[] pointArray){ // matches all Point instances for (Point(var x, var y) : pointArray) { System.out.println("(" + x + ", " + y + ")"); } } publicstaticvoidmain(String[] args){ noMatchExample(); System.out.println("---"); printUpperLeftColors(new Rectangle[] { new Rectangle(new ColoredPoint(new Point(1, 2), Color.RED), new ColoredPoint(new Point(3, 4), Color.BLUE)), new Rectangle(new ColoredPoint(new Point(5, 6), Color.GREEN), new ColoredPoint(new Point(7, 8), Color.BLUE)) }); System.out.println("---"); dump(new Point[] { new Point(1, 2), new Point(3, 4) }); } }
1 2 3 4 5 6 7 8 9 10
$ java --enable-preview --source 20 JEP432.java Note: JEP432.java uses preview features of Java SE 20. Note: Recompile with -Xlint:preview for details. p instanceof Pair(String s, String t) -> false --- RED GREEN --- (1, 2) (3, 4)
Listing 3
433: Pattern Matching for switch (Fourth Preview)
JEP 433 proposes a new feature that allows developers to use pattern matching in their switch statements. Essentially, this means that instead of just comparing a value to a series of constant values, developers can use more complex patterns to match against the value, including things like data types and structures like arrays or objects. This can make code more concise and easier to read [Listing 4], as developers can write more expressive code that directly matches against the data they are working with.
1 2 3 4 5 6 7 8 9
returnswitch (o) { casenull -> "Oops"; case Integer i -> String.format("int %d", i); case Long l -> String.format("long %d", l); case Double d -> String.format("double %f", d); case String s -> String.format("String %s", s); casePoint(int x, int y) p -> String.format("Point %s", s); default -> o.toString(); };
Listing 4 - See reference 2 for more code samples reference.
434: Foreign Function & Memory API (Second Preview)
This JEP proposes the addition of a new feature that allows developers to interface with native code and memory more efficiently. This means that Java applications can now use functions and data from other programming languages, such as C or C++, without the need for the complex and error-prone Java Native Interface (JNI).
The proposed API allows Java applications to directly access native code libraries and manage memory in a more efficient and controlled way (such as those provided by operating systems or third-party software vendors), without having to worry about compatibility issues or performance penalties.
In listing 5 you can see how the C library “strlen” function is called to retrieve the length of a string. It is a “nonsensical” example, but it does illustrate how it works. Most Java developers will probably rarely come into contact with the Foreign Function & Memory API.
import java.lang.foreign.*; import java.lang.invoke.MethodHandle; publicclassJEP434{ publicstaticvoidmain(String[] args)throws Throwable { // 1. Get a lookup object for commonly used libraries SymbolLookup stdlib = Linker.nativeLinker().defaultLookup(); // 2. Get a handle to the "strlen" function in the C standard library MethodHandle strlen = Linker.nativeLinker().downcallHandle( stdlib.find("strlen").orElseThrow(), FunctionDescriptor.of(ValueLayout.JAVA_LONG, ValueLayout.ADDRESS)); // 3. Convert Java String to C string and store it in off-heap memory try (Arena offHeap = Arena.openConfined()) { MemorySegment str = offHeap.allocateUtf8String("Java Magazine Rockz!"); // 4. Invoke the foreign function long len = (long) strlen.invoke(str); System.out.println("len = " + len); } // 5. Off-heap memory is deallocated at end of try-with-resources } }
1 2 3 4 5
$ javac --enable-preview --source 20 JEP434.java Note: JEP434.java uses preview features of Java SE 20. Note: Recompile with -Xlint:preview for details. $ java --enable-preview --enable-native-access=ALL-UNNAMED JEP434 len = 20
Listing 5
436: Virtual Threads (Second Preview)
Virtual Threads is an incubator feature introduced in Java SE 19 that allows for more efficient execution of concurrent code.
In simple terms, it allows multiple threads of code to run simultaneously without using up unnecessary resources. This can improve the performance and responsiveness of Java applications, especially those that require frequent and complex interactions between threads.
Virtual threads are lightweight threads that can be created and managed more easily than traditional threads, and they are designed to be more efficient in terms of memory and CPU usage. This makes it possible to scale applications more easily, and to handle more concurrent requests without sacrificing performance or stability.
Virtual Threads are not mapped 1:1 on an OS thread. Instead they are created and managed by the Java runtime. In the last Java Magazine a complete article was dedicated to this topic. [see Java Magazine 2023-01]
437: Structured Concurrency (Second Incubator)
This incubator feature enables better management of concurrent tasks in Java programs. With structured concurrency, tasks are organized into “scopes” to ensure that all tasks within a scope complete before the scope itself is considered complete.
This makes it easier to manage and control concurrent tasks, reducing the risk of problems such as race conditions and deadlocks. It also makes it easier to cancel or interrupt tasks within a scope without affecting other tasks, improving the overall stability and reliability of the program.
In simple terms, structured concurrency helps developers write more reliable and efficient code when dealing with multiple tasks that run concurrently.
In my article about Java 19 [reference 2 and 3] a code example is provided.
438: Vector API (Fifth Incubator)
This JEP is a proposed enhancement that aims to provide a new set of vector operations that can better utilise modern hardware platforms, such as SIMD (Single Instruction Multiple Data) and AVX (Advanced Vector Extensions) instruction sets.
The Vector API is designed to enable accelerated computations on supported hardware without requiring any specific platform knowledge or code specialization. The API aims to expose low-level vector operations in a simple and easy-to-use programming model, allowing performance optimizations to be integrated seamlessly into existing Java code.
The proposed API includes several key features, including support for variable-length vectors, a new set of mathematical operations, and a range of predicate and masking functions for data selection and manipulation. The API also includes support for hardware-specific features such as vector masks, and cache control operations.
Overall this JEP is aimed at improving the performance of Java applications on modern hardware, as well as providing a more convenient and efficient way to utilize advanced vector processing capabilities.
The first incubator was introduced in Java SE 16 and a code sample can be found at reference [2].
Conclusion
All the features mentioned in this article have potential and I am looking forward to using them. Let’s hope that all of them will become official features in the next version (21), which will be a Long Term Support (LTS) version.
]]>
<h1 id="Java-20"><a href="#Java-20" class="headerlink" title="Java 20"></a>Java 20</h1><p>Java SE 20 was released March 21, 2023, so it should be generally available when this article is published.</p>
<p>Most of the JEPs in this release have something to do with Pattern Matching or Virtual Threads and are resubmissions of already known Incubator and Preview features. This version doesn’t contain any new main features. The most exciting innovation in this release is called “Scoped Values” and is intended to widely replace thread-local variables.</p>
<p>In this article we will take a look at all the new and resubmitted Incubator and Preview features.</p>
<figure class="highlight shell"><table><tr><td class="gutter"><pre><span class="line">1</span><br><span class="line">2</span><br><span class="line">3</span><br><span class="line">4</span><br></pre></td><td class="code"><pre><span class="line"><span class="meta">$</span> docker run -it --rm \</span><br><span class="line"> -v $(pwd)/src:/src \</span><br><span class="line"> openjdk:20-slim /bin/bash</span><br><span class="line"><span class="meta">$</span> cd /src/java20</span><br></pre></td></tr></table></figure>
<p>Listing 1</p>
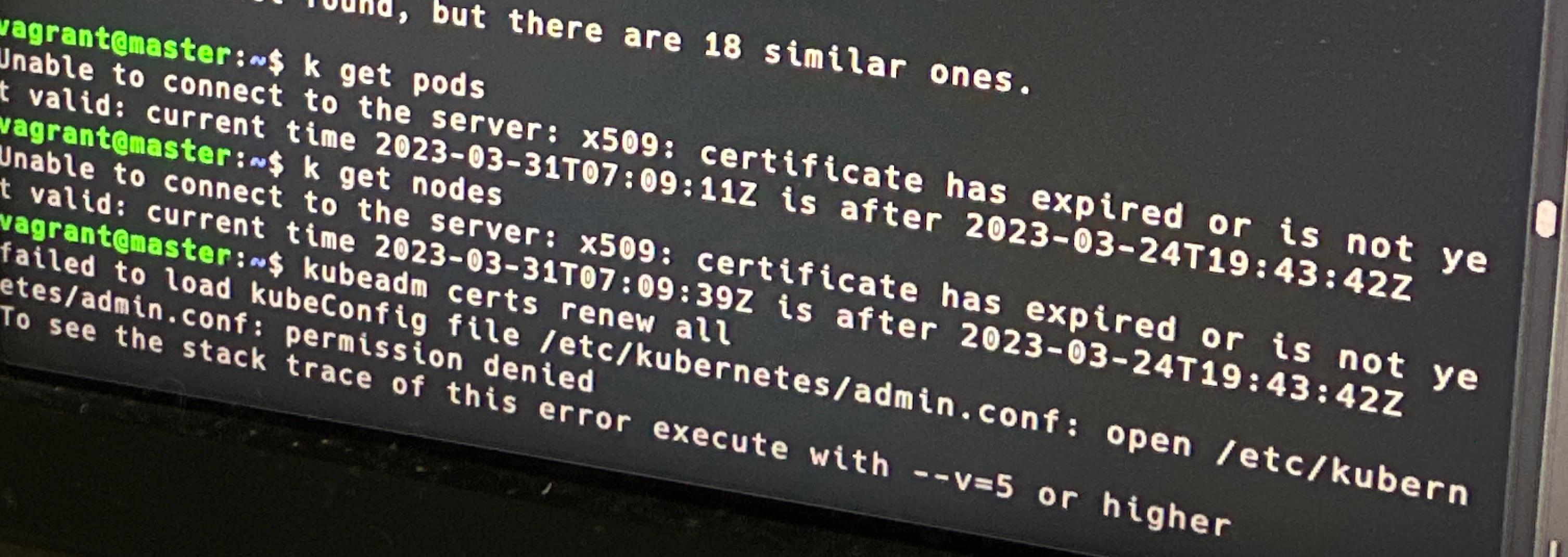
K8S: Unable To Connect To The Server: X509: Certificate Has Expired Or Is Not Yet Validhttp://www.ivonet.nl/2023/03/31/K8S-Unable-To-Connect-To-The-Server-X509-Certificate-Has-Expired-Or-Is-Not-Yet-Valid/2023-03-31T07:36:00.000Z2023-03-31T07:54:51.000ZK8S: Unable To Connect To The Server: X509: Certificate Has Expired Or Is Not Yet Valid
Problem
When trying to connect to a kubernetes cluster using kubectl, the following error is returned or something very similar:
1 2
$ k get pods Unable to connect to the server: x509: certificate has expired or is not yet valid: current time 2023-03-31T07:09:11Z is after 2023-03-24T19:43:42Z
Solution
The solution is to regenerate the certificates on the master node.
Regenerate the certificates
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
$ sudo kubeadm certs renew all [renew] Reading configuration from the cluster... [renew] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml' [renew] Error reading configuration from the Cluster. Falling back to default configuration
certificate embedded in the kubeconfig file for the admin to use and for kubeadm itself renewed certificate for serving the Kubernetes API renewed certificate the apiserver uses to access etcd renewed certificate for the API server to connect to kubelet renewed certificate embedded in the kubeconfig file for the controller manager to use renewed certificate for liveness probes to healthcheck etcd renewed certificate for etcd nodes to communicate with each other renewed certificate for serving etcd renewed certificate for the front proxy client renewed certificate embedded in the kubeconfig file for the scheduler manager to use renewed
Done renewing certificates. You must restart the kube-apiserver, kube-controller-manager, kube-scheduler and etcd, so that they can use the new certificates.
sudo kubeadm certs check-expiration [check-expiration] Reading configuration from the cluster... [check-expiration] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml' W0331 07:15:07.313285 2799806 utils.go:69] The recommended value for "resolvConf" in "KubeletConfiguration" is: /run/systemd/resolve/resolv.conf; the provided value is: /run/systemd/resolve/resolv.conf
CERTIFICATE EXPIRES RESIDUAL TIME CERTIFICATE AUTHORITY EXTERNALLY MANAGED admin.conf Mar 30, 2024 07:10 UTC 364d ca no apiserver Mar 30, 2024 07:10 UTC 364d ca no apiserver-etcd-client Mar 30, 2024 07:10 UTC 364d etcd-ca no apiserver-kubelet-client Mar 30, 2024 07:10 UTC 364d ca no controller-manager.conf Mar 30, 2024 07:10 UTC 364d ca no etcd-healthcheck-client Mar 30, 2024 07:10 UTC 364d etcd-ca no etcd-peer Mar 30, 2024 07:10 UTC 364d etcd-ca no etcd-server Mar 30, 2024 07:10 UTC 364d etcd-ca no front-proxy-client Mar 30, 2024 07:10 UTC 364d front-proxy-ca no scheduler.conf Mar 30, 2024 07:10 UTC 364d ca no
CERTIFICATE AUTHORITY EXPIRES RESIDUAL TIME EXTERNALLY MANAGED ca Mar 21, 2032 19:43 UTC 8y no etcd-ca Mar 21, 2032 19:43 UTC 8y no front-proxy-ca Mar 21, 2032 19:43 UTC 8y no
$ kubectl get nodes NAME STATUS ROLES AGE VERSION master Ready control-plane,master 371d v1.23.5 worker1 Ready <none> 371d v1.23.5 worker2 Ready <none> 371d v1.23.5
Conclusion
With a few simple commands, the certificates can be renewed and the cluster can be used again.
Note that I only tested this on my own cluster, so I can’t guarantee that this will work for you or if you have the rights to do this yourself. If you have any questions, please let me know in the comments.
]]>
<h1 id="K8S-Unable-To-Connect-To-The-Server-X509-Certificate-Has-Expired-Or-Is-Not-Yet-Valid"><a href="#K8S-Unable-To-Connect-To-The-Server-X509-Certificate-Has-Expired-Or-Is-Not-Yet-Valid" class="headerlink" title="K8S: Unable To Connect To The Server: X509: Certificate Has Expired Or Is Not Yet Valid"></a>K8S: Unable To Connect To The Server: X509: Certificate Has Expired Or Is Not Yet Valid</h1><p><img src="/images/2023/K8S-Unable-To-Connect-To-The-Server-X509-Certificate-Has-Expired-Or-Is-Not-Yet-Valid/K8S-Unable-To-Connect-To-The-Server-X509-Certificate-Has-Expired-Or-Is-Not-Yet-Valid.jpg" style="width:50%;height:50%;display: block;margin: 0 auto;"></p>
Java 19http://www.ivonet.nl/2022/12/13/Java-19/2022-12-13T18:07:00.000Z2022-12-13T07:58:26.000Z
JAVA 19
Yep, we’re another six months down the road, and it’s time for a new version of Java. Seven features (JEPs) are planned in Java SE 19. To play around with some Java SE 19 features (without having to actually install early access), all the code in this article is executed within a docker container running OpenJDK 19 [2], see Listing:
1 2 3 4
$ docker run -it --rm \ -v $(pwd)/src:/src \ openjdk:19-slim /bin/bash $ cd /src/java19
This article is divided into two main sections. The first section deals with new standard features. The second section discusses preview and incubator features. Normally there is a third section, where we talk about the features that are (going to be) phased out, but none have been announced for this release. For each feature, the JEP number will be listed.
NEW STANDARD FEATURES
Only one new feature has been announced in Java 19.
422: Linux/RISC-V Port. RISC-V (pronounced “Risk-five” in English) is a RISC instruction set architecture (ISA) originally developed at the Berkley University of California. The increasing availability of RISC-V hardware makes a port of the JDK valuable. In Java 19, this port will be complete and become part of the JDK.
PREVIEW AND INCUBATOR FEATURES
424: Foreign Function & Memory API (Preview).
This JEP replaces two previous incubation APIs: the Foreign Memory Access API (JEPs 370, 383 and 393) and Foreign Linker API (JEP 389). The earlier incubations failed. The goal of this JEP is to create and provide a more user-friendly and general-purpose API for dealing with code and data outside of JVM.
426: Vector API (Fourth Incubator).
This JEP is the fourth incubator of an API to compile vector accounts into optimal vector instructions on supported CPU architectures. This phase focuses primarily on improvements from feedback and on improved implementation and performance. This JEP builds on JEP 417 from Java SE 18, JEP414 from Java 17, and JEP 338 introduced in Java SE 16. See reference [2] for sample code.
405: Record Patterns (Preview).
Java 16 was extended with a “type pattern test” through JEP 394. In Java 17 and 18, the switch-case-statement has also been developed with it, via JEP 406 and 420, respectively; see reference [3] for code examples.
Using Type Pattern will remove the need for type-casting in most cases. However, this is only the first step toward a more declarative, data-oriented programming style. Since Java now uses records to support a more expressive way of modeling data, pattern matching can make data easier to use by enabling them to express semantic intent in their models, see next listing
This is the third preview of pattern matching for switch statements that was first released in Java 17 in JEP 406 and its second preview received in Java 18 in JEP 420. In this third preview, mainly minor improvements have been made based on user feedback and user experience. Check out the sample code[2] and the Java 17 article [3].
425: Virtual Threads (Preview)
Virtual Threads are part of project Loom [4]. Project Loom is aimed at improving concurrency performance in Java by letting the developer write concurrency applications with known APIs to write, maintain and use hardware resources more efficiently.
Virtual Threads are new, lightweight implementations of Java’s thread class that are scheduled by the JDK, rather than by the operating system (OS), as has been the case so far in Java. Sample code is omitted here because you can read a whole article about it in the next Java Magazine.
publicstaticvoidmain(String[] args)throws InterruptedException { final AtomicInteger atomicInteger = new AtomicInteger(); Instant start = Instant.now(); try (var executor = Executors.newVirtualThreadPerTaskExecutor()) { for (int i = 0; i < 10_000; i++) { executor.submit(sleepyHead(atomicInteger)); } } Instant finish = Instant.now(); long timeElapsed = Duration.between(start, finish).toMillis(); System.out.println("Total elapsed time : " + timeElapsed / 1000.0 + " seconds"); } }
1 2 3 4 5 6 7 8
$ java --enable-preview --source 19 JEP425.java [...] Work done - 9996 Work done - 9997 Work done - 9998 Work done - 9999 Work done - 9989 Total elapsed time : 1.471 seconds
428: Structured Concurrency (Incubator)
The idea behind Structured Concurrency is to make the lifetime of one or more threads work the same as a code block in structured programming. Structured Concurrency treats multiple tasks in different threads as a single unit of work, which streamlines error handling, which improves reliability and observability (debugging).
The listing above gives three examples of a ‘foo-method’. One where it’s called in a multithreaded method, and one where Structured Concurrency is applied. In the fooSequential- method, it is abundantly clear to the average developer what happens if an exception occurs in one of the statements. FooSequential will fail on that statement.
How fooThreaded fails if, for example, in baz() an exception is thrown is a lot harder to understand. The threads must, in fact, completely resolve before the foo-method will propagate the error. Namely, it will first evaluate bar() and it will only return after two seconds. This is because the baz and bar calls run in isolation. It goes even further. Suppose that this foo-method itself fails before the joining calls are made. Then foo will already fail, but the threads will just continue.
In the fooStructured-method, the created threads are seen as one unit of work, and the foo method will immediately return if any of the other calls fail.
In Listing below, where the code is run without an exception being thrown, you can see that the Sequential call takes more than 2500ms because bar and baz are called one after the other.
1 2 3 4 5 6 7 8 9 10
$ java --enable-preview --source 19 --add-modules jdk.incubator.concurrent JEP428.java WARNING: Using incubator modules: jdk.incubator.concurrent warning: using incubating module(s): jdk.incubator.concurrent 1 warning bazbar Sequential took 2504 ms barbaz Threaded took 2008 ms barbaz Structured took 2062 ms
There is not much difference between Threaded and Structured. However, the big difference becomes obvious as soon as something does go wrong (Listing below). Then you can see that when using Structured Concurrency, the foo method fails, as soon as the first exception is thrown (in the baz method).
1 2 3 4 5 6 7 8
$ java —source 19 —enable-preview \ —add-modules jdk.incubator.concurrent JEP428.java Interrupted in sequential Sequential took 2512 ms Interrupted in threaded Threaded took 2019 ms Interrupted in structured Structured took 531 ms
CONCLUSION
Lots of incubators and preview features in this version of Java, but also some really high potential features with a lot of promise. If the Virtual Threads and Structured Concurrency make it to the core of Java, then that bodes well. Multi threaded work as if you were just doing structured programming. I’m in favor!
]]>
<p><img src="/images/2022/java-19/java-19.png" style="width:50%;height:50%;display: block;margin: 0 auto;"></p>
<h1 id="JAVA-19"><a href="#JAVA-19" class="headerlink" title="JAVA 19"></a>JAVA 19</h1><p>Yep, we’re another six months down the road, and it’s time for a new version of Java. Seven features (JEPs) are planned in Java SE 19.<br>To play around with some Java SE 19 features (without having to actually install early access), all the code in this article is executed within a docker container running OpenJDK 19 [2], see Listing:</p>
<figure class="highlight shell"><table><tr><td class="gutter"><pre><span class="line">1</span><br><span class="line">2</span><br><span class="line">3</span><br><span class="line">4</span><br></pre></td><td class="code"><pre><span class="line"><span class="meta">$</span> docker run -it --rm \</span><br><span class="line"> -v $(pwd)/src:/src \</span><br><span class="line"> openjdk:19-slim /bin/bash</span><br><span class="line"><span class="meta">$</span> cd /src/java19</span><br></pre></td></tr></table></figure>
JFall 2022http://www.ivonet.nl/2022/11/03/jfall-2022/2022-11-03T08:07:00.000Z2022-11-04T09:56:09.000Z
An impression of JFall by yours truly.
keynote
Sold out!
Packet room!
Very nice first keynote speaker by Saby Sengupta about the path to transform. He is a really nice storyteller. He had us going.
Dutch people, wooden shoes, wooden hat, would not listen
Saby
lol
Get the answer to three why questions. If the answers stop after the first why. It may not be a good idea.
This great first keynote is followed by the very well known Venkat Subramaniam about The Art of Simplicity.
The question is not what can we add? But What can we remove?
Simple fails less
Simple is elegant
All in al a great keynote! Loved it.
Design Patterns in the light of Lambdas
By Venkat Subramaniam
The GOF are kind of the grand parents of our industry. The worst thing they have done is write the damn book. — Venkat
The quote is in the context of that writing down grandmas fantastic recipe does not work as it is based on the skill of grandma and not the exact amount of the ingredients.
The cleanup is the responsibility of the Resource class. Much better than asking developers to take care of it. It will be forgotten!
The more powerful a language becomes the less we need to talk about patterns. Patterns become practices we use. We do not need to put in extra effort.
I love his way of presenting, but this is the one of those times - I guess - that he is hampered by his own succes. The talk did not go deep into stuff. During his talk I just about covered 5 not too difficult subjects. I missed his speed and depth.
Still a great talk though.
lunch
Was actually very nice!
NLJUG update keynote
The Java Magazine was mentioned we (as Editors) had to shout for that!
Please contact me (@ivonet) if you have ambitions to either be an author or maybe even as a fellow editor of the magazine. We are searching for a new Editor now.
Then the voting for the Innovation Awards.
I kinda missed the next keynote by ING because I was playing with a rubix cube and I did not really like his talk
jakarta EE 10 platform
by Ivar Grimstad
Ivar talks about the specification of Jakarta EE.
To create a lite version of CDI it is possible to start doing things at build time and facilitate other tools like GraalVM and Quarkus.
He gives nice demos on how to migrate code to work in de jakarta namespace.
To start your own Jakarta EE application just go to start.jakarta.ee en follow the very simple UI instructions
I am very proud to be the creator of that UI. Thanks, Ivar for giving me a shoutout for that during your talk. More cool stuff will follow soon.
Be prepared to do some namespace changes when moving from Java EE 8 to Jakarta EE.
I had a fantastic day. For me, it is mainly about the community and seeing all the people I know in the community. I totally love the vibe of the conference and I think it is one of the best organized venues.
See you at JSpring.
Ivo.
]]>
<p><img src="/images/2022/jfall-2022/jfall-2022_1.jpg" style="width:50%;height:50%;display: block;margin: 0 auto;"></p>
<p>An impression of JFall by yours truly.</p>
JavaOne 2022http://www.ivonet.nl/2022/10/18/javaone-2022/2022-10-18T05:44:00.000Z2022-11-04T07:06:50.000ZNotes
My ideas and thoughts about JavaOne 2022 at Oracle Cloudworld.
Day 1 - the one without bread
Breakfast
Breakfast started with a brisk walk to the venetian hall. There we received a protein box with an weird combination of food stuffs. Peanut butter without something to put it on. Cheese without something to put it on. Salt, why, just why? Some grapes, which was nice. Some turkey roll without something to put it on. In essence where was the bread?
Keynote
Impressive start with lots of video and dance
“Being bold wil make you win. By being timid will make you loose. “ —
Many of the big customers and partners received their spot on stage like:
NVidea
Deutsche Bank
Grupo Bimbo
Johnson Controls
Melissa & Doug
Team Max Vestappen
Java Keynote
Nice keynote but I am shocked at how small it has become. Is this because there was no open CFP? Or is it something else? I do not know, but I have questions…
Java after Eleven
Lunch
Was actually very nice with pasta, fish or chicken and a very good desert. Chocolate thingy that was awesome.
Cleaning your code with records, sealed classes and Pattern Matching
Jose Paumard clearly knows what he is talking about and he gave a great talk about cleaning your code with pattern matching in combination with records and sealed classes, even though we were really bothered by the load music, that already started while there were still sessions going on. Not cool Oracle.
welcome party
Well it started a bit early and the music bothered the speakers, but other than that it was really nice with drinks and tasty food stuffs.
Race between pair programming tools
Kaya Weers had a great talk about pair programming tools. In a short amount of time she showed us in a fun way what the most popular tools can and can not do. Very nice.
Day 1 - Conclusion
I was shocked about how small the JavaOne part has become. I think the lack of open CFP has contributed hugely to that.
Other than that it was a really nice day. I have been inspired by nice talks and fun people I spoke with.
Why though do Oracle employees get preferential treatment when standing in line? That is a question 🤣. I have no answer.
Day 2 - The one with hacking a lot
Hacker-garden with Ivar Grimstad
I was working with Ivar in het Hacker-garden on the Eclipse starter project. I was able to contribute a simple UI on the project.
The actual archetypes will follow very soon.
It was an awesome experience and I had a great and productive time with Ivar and Josh Juneau.
Lunch
Very good lunch
Clean your code as you code
Tom Howlett
Sonarlint
Sonarqube
Sonarcloud
It was a good talk but too bad it was mainly a product promotion.
Day 3 - the one with …
The sincerest form of flattery
It is very difficult to add functionality to an existing language.
Covariant typing - variance
Hmm from the moment patters were discussed it went int the same talk as earlier in the conference.
Community keynote
Very nice to see the familiar faces. Too bad it has become so small. I really hope that this year is a step up to better times.
Brian Vermeer also said “goedemorgen” and started mixing drinks for the attendees.
HOL about project Loom
Virtual threats. Very nice hands on lab
Things I didn’t know about Java
So much fun!
Conclusion
I can not deny that I was shocked and disappointed about the reduction in size of JavaOne. Also not making the CFP open to the general public is bad form and should not continue.
Despite that it was actually a nice conference. I loved hacking in the hacker garden with Ivar Grimstad and Josh Juneau for the Jakarta EE archetypes.
]]>
<h1 id="Notes"><a href="#Notes" class="headerlink" title="Notes"></a>Notes</h1><p><img src="/images/2022/javaone-2022/javaone-2022.jpg" style="width:50%;height:50%;display: block;margin: 0 auto;"></p>
<p>My ideas and thoughts about JavaOne 2022 at Oracle Cloudworld. </p>
Java EE - Jakarta EE Initializrhttp://www.ivonet.nl/2022/05/05/javaee---jakarta-ee-initializr/2022-05-05T14:22:32.000Z2022-05-05T14:23:40.000Z
Getting started with Jakarta EE just became even easier!
Moved from the Apache 2 license to the Eclipse Public License v2 for the newest version of the archetype as described below. As a start for a possible collaboration with the Eclipse start project.
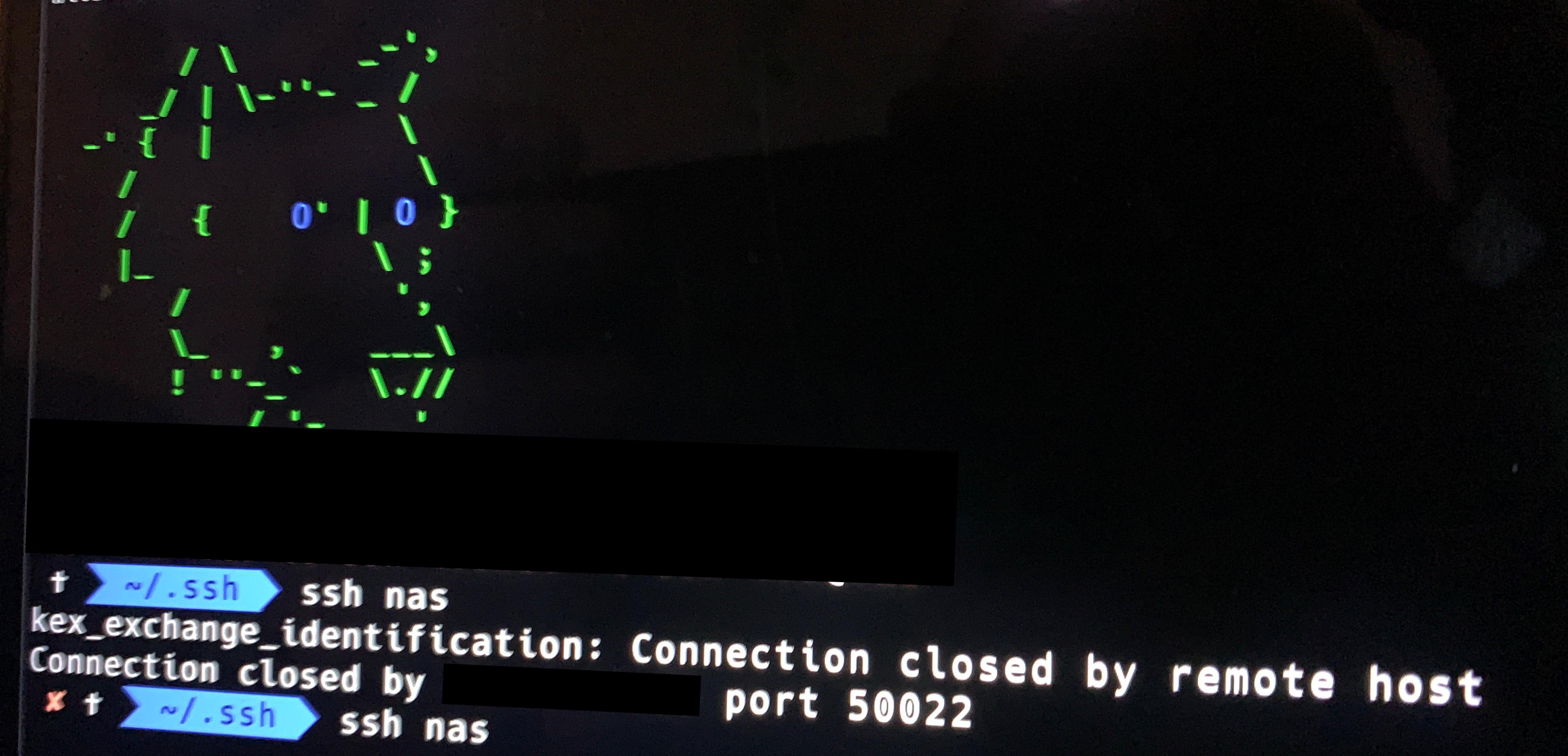
You want to log into your Synology Nas through ssh and get the above message.
Solution
The IP address you are currently on has probably been blocked by trying too many times when configuring the ssh connection.
The Synology NAS has this auto block function that adds IPs to the block list that have tried too much.
how to check and Fix
On the host machine go in a browser to the following address to see what your IP is ipecho.net.
Copy the IP address from the browser and go to the DSM of your nas. Goto Control panel > Security > Protection > Allow/Block list > Block list > Search > paste the ip > if ip in Block list then remove.
You want to make a multi platform docker image but the emulation on your Apple M1 is not bulletproof. How to get around this issue is explained in this blog post…
Problem
I have the new Apple M1 MacBook fancy smancy laptop workhorse. The M1 (aarch64) processor is very fast and very friendly on the battery, but there are also some - not so small - issues associated with working on a new chip architecture.
I’ve tried to create a few multi-platform docker images with buildx and some are just not correctly emulated on the M1. The parallelism of buildx was also an issue but the emulation gave me the most trouble.
Solution
Use buildx (remote) nodes to build on native architecture.
What do you need
More than one docker enabled device in your network like:
Nas
RaspberryPi
Other laptop / PC
ssh access to these devices
In my case I have a Synology NAS that is amd64/x86_64 based and my own M1 that is arm64/aarch64 based.
How
Step 1: Installation
Buildx (buildkit) is since the newer versions of Docker a buildin function. You can check this with the following command.
1 2
$ docker buildx version github.com/docker/buildx v0.8.1 5fac64c2c49dae1320f2b51f1a899ca451935554
On my nas docker version 20.10.3 is running but no buildx is available. This is not an issue as my nas will be a worker node. We will revisit that in a later step.
Step 2: Setup ssh for your docker worker node
The remote host where we also want to run Docker needs to be configured with a password-less ssh connections. This blog will not explain how to do that as there are many blogs explaining how to set up a public/private key access to a device.
if you already have the keys you can copy them to your target device like so:
1
ssh-copy-id username@target_host
In order to run a command with the user environment available you need to make sure your sshd service allows it. When running a command through ssh you will have a limited environment and that needs to be adjusted.
In order to have a correct environment where docker is known you need to set the #PermitUserEnvironment no property to PermitUserEnvironment yes in the /etc/ssh/sshd_conf file on your NAS. When this is adjusted you need to restart the sshd service
on my Synology nas I used this command. It might be different for your device:
1
sudo systemctl restart sshd.service
Now you have to set the environment for ssh:
login to your nas through the terminal (ssh USER_HERE@NAS_HOST_HERE)
cd ~/.ssh
create a file called environment with the following value in it
1
PATH=/usr/bin:/bin:/usr/sbin:/sbin:/usr/local/bin
the last /usr/local/bin is where the docker command lives. So now it will be available.
Check if you can run docker with the command below. It should work:
1
docker -H ssh://USERNAME_HERE@NAS_HOST_HERE info
Do not forget to change the values in the command to appropriate values for your situation.
Step 3: Create a buildx local node
Let’s first create the local platform. In my case that is the Apple M1 node. It should build all the arm64/aarch64 targets.
In my case this will be the amd64/x86_64 builder node. The platforms corresponding to that architecture should be send there. We have already configured the ssh access and the environment and tested that docker can access it.
The command below will build for amd64 and arm64 but will direct the amd64 build to the remote node and the arm64 build will be done on the local machine.
This will result in something like this on the docker hub:
Conclusion
The most obvious issue in this setup is that I can only build for multiple platforms when within my own network. That is not necessarily true if you used a remote ssh accessible host or IP. I did not do that and that limits me to these builds when I have my remote node available in the network. For now that is not a real issue for me.
My NAS is quite a bit slower that my Apple M1 so the builds are slower.
It solved my concurrency problem. I had one build where I had to start the server, in order to configure it, during the docker build. Buildx does this in parallel and that gave me a port conflict as one was a bit faster but not ready when the other also tried to start. That was a problem when I tried to build all on only my local node. When I added the remote node this problem went away as the port was used on a completely different machine.
All in all I am very happy with this solution for now.
]]>
<p><img src="/images/2022/docker-multi-platform-build-with-buildx/docker-multi-platform-build-with-buildx.png" style="width:50%;height:50%;display: block;margin: 0 auto;"></p>
<p>You want to make a multi platform docker image but the emulation on your Apple M1 is not bulletproof. How to get around this issue is explained in this blog post…</p>
Refactoring code vs Rewrite of codehttp://www.ivonet.nl/2022/03/18/Refactoring-vs-rewrite-of-code/2022-03-18T19:24:33.000Z2022-04-10T19:29:43.000Z Should you refactor existing code or rewrite?
A difficult decision to make when confronted with software problems
Intro
Recent history and experience teaches us that almost all software will build up technical dept over time due to inexperienced programmers, bad or neglected regular maintenance, pressing deadlines, unwanted but expensive features, dead code never removed, laws and regulations and many other reasons.
So what to do? Do we refactor the existing code to manageable levels or do we rewrite everything? Often it seems an easy choice to make, but experience learns that most of the time these choices have far-reaching effects and entail much more than the simple choice to do the one or the other. Should it be a choice for either one or can there be a combination of the two? can we prevent the build up of technical dept completely?
In this blog post I will try to dive a bit into what the choices are and what the possible Pro’s and Cons and possible consequences are of the choices.
Both options have their advantages and disadvantages. Rewriting code makes it possible to completely change the architectural setup of a system, but can lead to breaking the product if not done right. Refactoring can keep the code manageable without having to change everything, but may not make it easy to work with emerging technologies or languages.
Refactoring and rewriting code are not enemies of each other, and you should never choose on over the other for everything. Often it can be a combination of the two and the circumstances of the code, technology and the team should determine what will be done.
Let’s look at some of the Pro’s and Con’s of refactoring and rewriting code and try to see of we can distill some guidelines from them
Refactoring Code
Code refactoring is the process of restructuring existing code - changing the factoring - without changing its external behavior. Refactoring is intended to improve the design, structure and/or implementation of the software, while preserving its functionality. – wikipedia
So refactoring is always done on existing code, but that does not mean it needs to be old code. Refactoring can be done on code that has just been written but can be improved on. Extreme programming actually advocates this and stresses continues refactoring.
Refactoring the code is mainly for the developers not necessarily for the compiler. Refactoring is to make the code easier to understand by other developers and to make it more trustworthy because of it.
Some reasons to choose refactoring:
Reinventing something that already exists is useless
No information available about the feature(s)
No information about requirements
The user experience is not impacted
There is no guarantee that rewriting will improve the quality
The current code is already “proven”. At least in production.
Advantages of refactoring
Improved readability. Refactoring should always make the code more readable for other developers.
Reduced complexity. A good reason to refactor is to reduce complexity while maintaining the functionality.
Improved maintainability. When you achieve the above two the maintainability will immediately go up.
Improved extensibility. When trust in the software grows it is less of an obstacle to overcome to make changes.
Refactoring can be done at any time. You can do a major overhaul of a piece of software or just refactor the small part of the code a developer is working on at the time. Refactoring does not have to cost much if it is part of the daily life of a developer.
Refactoring can be done on any type of codebase. It does not matter if it is a Monolithic system or a distributed system.
The code is already in production and the way to production is already known. You are improving “proven” code.
Disadvantages of refactoring
Refactoring does not fix architectural problems already in the software. It can improve its functionality within that architecture but not change it. e.g. Code written in COBOL will still be written in COBOL even when refactoring.
In order to effectively refactor code you need to be able to trust that you will not change the functionality of the code during your refactoring. Trust can only be gained by extensive unit testing and if that is not part of the normal flow of development this can be a major investment.
Refactoring is as strong as the skill of the developer. It requires skill and courage and can look daunting to less experienced programmers. Less experienced programmers may even experience it as a waste of their time as “the code already works right?”.
So refactoring is very useful in many ways, but requires discipline, skill and an extensive test suite. When happy with architectural choices made it is a great way to keep the code up to par and maintainable. When architectural changes are required by whatever reason it is time to start looking at rewriting the code.
Rewriting code
Rewriting code is exactly that. Instead of trying to better the existing code we can choose to write new code. Unlike refactoring, code rewrites seem straight forward. The developer just starts over right? Spoiler alert… it isn’t! You are not actually starting a greenfield project, but are developing a new system based on strict requirements. Requirements not always clear but still strict as you already have a customer base.
There are many reasons to want to rewrite code.
Good reasons:
The language must be changed
The source code is not available (anymore)
The code is difficult to understand
The source code has become a problem
New technologies are wanted or needed
A new platform is wanted or needed
Debugging has become difficult
The code has build a large technical depth
To stimulate your developers group
Copyrights or licensing issues
It does not compile anymore
Architecture needs to change significantly
Resources are very hard to find
Bad reasons:
Dislike of how the code looks
Laziness
Not written by “me” (Not invented here problem)
Application is too slow
Lack of respect for the former creators
Ugliness
To successfully rewrite software, you need to maintain the current production software and write the new system at the same time. So that means two teams at least. One to write the new system and one to maintain the current one. Effectively duplicating a lot of resources and that is not all! The current (old) production system will need to keep working. Sometimes for years to come depending on the size of the system. It may need to even bring out new features due to e.g. new laws or prior agreements with customers. The rewrite team must constantly adjust to these changes too. With the rewrite of the system come new feature requests.
Advantages of rewriting code
You can utilise the latest and greatest technologies, language(s) and frameworks while rewriting the code. It opens the way to the newest platforms like cloud, web and mobile and that opens the way to new markets and customers.
It eliminates the need to try to fit unfit code unto these new technologies and needs.
A new start also gives developers the change to do it right from the start and write their code with maintainability, readability and testability in mind. It makes it much easier to be proud of your work and stay proud.
Starting new makes it possible to review important decisions from the past. It makes it way easier to adapt to new development approaches. It bridges the gap between legacy and new technologies.
Avoiding past mistakes
Fresh application design
Disadvantages of rewriting code
Effort! Rewriting code takes time and effort and lots of it. Rewriting code is not the same as adding new features. You may have to invest years to be at the same level as you were with the old code with the one distinction that you are now ready for the future. It is very difficult to explain to management that you need to “fix” a working clock. Management must be very committed to make this work. They must make this decision being well-informed. Rewriting often takes much longer than expected.
You may need to write temporary code to sync production to the new system constantly while the old system is still the leading software. You may need to write code that validates these syncs. You may want to shadow run in production for a time to gain confidence and trust. A lot of extra effort for no direct customer value.
As you are probably moving to more modern technologies and therefore changing a lot of the requirements, your customers also need to change with you in this process and probably be made part of the change process. They also need to know what the effort entails. Involving customers will not make this process easier but is probably unavoidable. This requires careful management of expectations and may be a real bottleneck. New suggest better, but that might not be the case at first. Stakeholder expectation management is needed. Return of investment is not always clearly evident.
The gap between the team maintaining the production software (legacy) and the team building the new system can grow and that can cause problems on more personal levels like for example motivation. It is important to make the maintenance team an integral part of the migration. They can, sometimes rightly so, feel threatened.
Old code will probably become even uglier. Refactoring of the code is stopped and only minimal effort is put into keeping it running just long enough for the new code to replace it even though this may take years. That makes rewriting code a real commitment. Prematurely stopping this process, for any reason, can be more costly than imagined, because during this period the actual production code can have deteriorated a lot.
It might therefore be necessary to do more than only keep it running if you want to keep your competitiveness on the market. If you do not, you may give your competitors a free head start.
A rewrite may not guarantee great new code. Often a completely new skillset is required for the new codebase. A skillset that may not be present within the company. A skill that needs to be learned. How will we learn? Is a course enough or do you need experienced senior developers already versed in these new technologies? Is that a possibility? If this part is not done right you will start rebuilding your technical dept immediately and have the same problems again soon. Often with disastrous effect even before the rewrite has completed.
Risk of missing features. Documentation is often unmaintained and therefore untrustworthy, but you are actually rewriting a system with strict requirements for your existing customers. The production (old) code may therefore be the only proven source of knowledge left of the system other than the developers working on it. It is very possible to need to dive into the code on a very detailed level to distil the information needed to be able to rewrite it in the new form. When a system has existed for quite a few year already there are guaranteed to be many surprises there that can effect the new code and the choices made.
Risk (surety) of new bugs.
Risk of breaking other code that uses your software.
New environment means new pipeline, install scripts, skills, documentation, etc.
A difficult choice
Yes the choice to rewrite the code is a difficult one. It should be. The consequences of this choice are big and should not be taken lightly. This does not mean that it must never be done. As described above many good reasons exist.
If you want to rewrite your code but want to stay on the same technology stack, you may want to reconsider that choice. Refactoring is probably a much better choice in that case.
Often a team will shout for a rewrite in the hope to escape the mess they themselves are accountable for. It is a good idea to verify this independently. If a rewrite is rewarded chances are high it will lead to the same situation of creeping technical dept. A waste of money, time and resources.
Experience learns that rewriting software with the same development team that produced the original version is seldom a good idea. As rewriting most likely requires a new set of skills it is ignorant to assume that the current development team is up to it. Before diving in it is a very good idea to research what the new technology stack will become and plan accordingly. Invest in schooling but also in the right resources.
If you have a large system to rewrite it is probably a good idea to hire a team of well-suited software engineers and provide them with the business knowledge from within the company. In the long run it is simply worth paying extra for experienced developers who have previously worked on projects with complex domains and large codebases. Such experienced and seasoned developers can help you through the process and ask smart questions. Mix them with your own employees so that they can absorb the way of working by being led by example.
Make sure you at least have a somewhat vaguely clear end-goal (vision). I say this with care as I do not advocate to go back to a waterfall based development, but when going for a rewrite it is necessary to have an idea of…
a product roadmap
of the technology stack you want to work with (conform marked standards)
the complete set of features
a working knowledge of your domain from a business standpoint
hopefully an idea of user journeys…
Knowing the above it will be much easier for engineers to make informed architectural decisions.
Know the value of a Minimal Viable Product and make sure to define this MVP with all stakeholders.
Be professional and try to leave ego’s behind.
]]>
<p><img src="/images/2022/Refactoring-vs-rewrite-of-code/Refactoring-vs-rewrite-of-code_0.png" style="width:50%;
height:50%;display: block;margin: 0 auto;"><br>Should you refactor existing code or rewrite?</p>
<p>A difficult decision to make when confronted with software problems</p>
J-Fall 2021http://www.ivonet.nl/2021/11/04/j-fall-2021/2021-11-04T08:26:00.000Z2021-11-04T19:19:29.000Z
J-Fall 2022 live blog
It has started!
I just went to the talk from Koen Aerts about littil which was about Devoxx 4 Kids and some nice ideas about evolving that.
Third place goes to Streammachine! Second place goes to ANWB Dienstverlener Beheer
And the winner is:
Picnic!
Masters of Java 2021
Give a very nice video impression of the Dutch java “championship”.
And the winner is:
Were on none of the posted questions the fastest but they were consistently good.
This was their third win in a row!!!
This ended the very nice keynote!!
Coffee ☕️ (Java) time
intermezzo
Sry no updates at this time. I am going over my own talk that I will give in about half an hour
Java - a journey through time
After my talk I spoke to so many other attendees that I completely lost track of time. Missed most of the other talks and just enjoyed the conference itself. I have missed this more that I realized.
A blog about how to get certified as a Kubernetes developer (CKAD) with handy tips and tricks along the way
Intro
I was lucky. I already had extensive knowledge of Docker before starting the certification for Kubernetes developer (CKAD), and I have an employer (Ordina) that gives me the space and time to invest in myself.
So I claimed a week of preparation and did the whole Kubernetes for Developers (LFD259) course. To follow this course you have to prepare a practice environment, and you are given instructions on how to do that on AWS or Google Cloud (can result in extra costs). It is also very possible to create a cluster on your own machine. To make my life easier (and cheaper) I opted for the last option and created a vagrant setup for it here.
The LFD259 course covers everything needed for the certification, and it is created by the organisation also responsible for the certification exam. Much of the course is self study and reading. One of the downsides of this course was that if something went wrong, and you had a question you had to ask it on a forum and responses to that forum could take a long time.
So to prepare even more I bought the Udemy course Kubernetes Certified Application Developer (CKAD) with Tests. Normally this course is about $200,= but I bought it in a bundle (with Kubernetes for Administrators - CKA) for about $35,= A good deal as far as I am concerned. Udemy excels in video courses and that visualisation made the needed knowledge complete.
A nice extra of the Udemy course was that it came with prepared exercises on KodeKloud. Very nice! and with practice exams and lightning labs.
After a week of following courses and practicing a lot I scheduled the exam. In all honesty I was quite nervous. I scheduled my exam a week later for some extra practice and that is what I did.
Practice practice practice. Speed is what you need. All the blogs I read stressed that point, and I concur 😄.
Tips & Tricks
I have created a GitHub page with all the resources I used, with an extensive list of tips and tricks.
Practice for speed!
The biggest challenge is getting it all done within the allotted time. You have to complete 19 questions in 2 hours and in that time you have to write YAML files and edit them in one of the basic linux editors (vi / nano). I recommend investing in vi knowledge as it is much more powerful than nano.
The mentioned udemy course has a few lightning labs at the end of the course. If you can finish them within the given time you are very good on track.
Use kubectl over YAML as much as you can
YAML is a pain to write and cut and paste can be a hassle with mixed tab and whitespace characters. So much can go wrong here!
Please don’t write YAML files from scratch!
Use kubectl run with the dry-run (--dry-run=client -o yaml) option whenever you can to at least generate as much of the YAML as you can. Practice this a lot and find more options.
1 2 3 4 5
# this is much faster kubectl create deploy mydeploy --image=nginx --port=80 --replicas=4 #than kubectl create deployment mydeploy --image=nginx --port=80 kubectl scale deployment mydeploy --replicas=4
and if you need to add more options not provided from the commandline use the dry-run:
1 2 3
kubectl create deploy mydeploy --image=nginx --port=80 --replicas=4 --dry-run=client -o yaml>mydeploy.yml vi mydeploy.yml # edit what you need done and apply/create
Create a good set of bookmarks
You are allowed to have the kubernetes.io docs open in a second tab during the exam and this is powerful stuff. Create an extensive set of bookmarks pointing to all the needed examples. I have exported the bookmarks I used during my exam, and it was pure gold! Very useful.
Use bash to the fullest
Typing --dry-run=client -o yaml is very cumbersome every time you want a dry-run to generate a YAML but by putting it in a variable it becomes easy.
This is just very basic stuff but saves a lot of time.
If you want to get more fancy do more!
1 2 3 4 5 6 7 8 9
source <(kubectl completion bash) #setting the namespace (just do this one again for another namespace if needed) export NS=default # You will do dry runs often and now you can just type $DR in stead of the whole thing export DR='--dry-run=client -o yaml' # use k to run the kubectl command in the exported namespace. Saves typing alias k='kubectl -n $NS' # Now get code completion on the 'k' commands complete -F __start_kubectl k
Now, this is a setup made for speed 😄!
You can use k instead of kubectl with bash completion (tab) on the command, and you can make it into a dry-run by just adding $DR to it. If you have to perform multiple commands on a different namespace just perform this command first NS=otherns and use k again as normal. All this demands practice, because you must not forget to change back to the default namespace again when needed, but they can be great time savers.
Useful resources
CKAD-Resources - For many more tips tricks and useful links
k8s-cluster - For a local VirtualBox/vagrant based k8s cluster
]]>
<p><img src="/images/2021/kubernetes-for-developers/kubernetes-for-developers.png" style="width:50%;height:50%;display: block;margin: 0 auto;" alt="Kubernetes for developers"></p>
<p>A blog about how to get certified as a Kubernetes developer (CKAD) with handy tips and tricks along the way</p>
Open "Unidentified Developer" Apps On Your Machttp://www.ivonet.nl/2021/03/21/open-unidentified-developer-apps-on-your-mac/2021-03-21T08:53:00.000Z2021-04-18T10:48:11.000Z
Problem
Writing free software for macOS is impossible because a developer (like me) first needs to become part of the “Apple Developer Program” to sign Applications and that costs $99,== a year.
A lot has been said about this subject and some Apple fanboys/girls will say that this is a sensible way for Apple to control software quality. To some extent I would even agree as a valid certificate shows that your software hasn’t been tampered with and, if it turns out to be malware, Apple can revoke your certificate.
The cynic in me though also sees it as a way to extort $99,= a year for each developer out there. How can I have my creations effectively distributed for fee if I can not sign it for free? That would make it less than free for me and ruin the fun in my hobby projects…
Solutions
Option 1 - Ask money for it
The thing is that if I start asking money for my hobby projects it is not a hobby anymore but a business. What happens if you buy my software? You expect support right? of course, you do. I would too. The beauty of writing Open Source software is that I don’t have to, but can if I choose. Some of my hobby projects die after a time, either because I don’t use them anymore or other projects are more fun to do. Whatever the reason I can stop with a project whenever I want to. Users can still benefit though, because if they really want to they can improve or build it themselves and continue using it. So this solution of asking money for software brings too many obligations with it and that would kill the hobby. Not an option.
Option 2 - Only source code
I can distribute my projects as “only source code” through media like github.com and I actually do. The issue with this one though is that the conversion rate of using my software will probably be very low. Only those really interested in a specific project and with the knowledge to compile/build etc. will be able to make it work. That is probably a very low percentage of the total possible user base. A part of the fun of hobby projects, for me at least, is to see that others like it too and have fun with it. So I want my user base as large as possible. That means that I need to create a distribution for easy installation….. and that needs Signed Software…. pfff and we are back at the beginning.
Option 3 - Donations
Ask for donations. Very insecure as I have no idea if my software will be used, and I don’t beg. I would also have to do marketing and stuff and that is not why I write software. I write software for myself and if others like it that makes it more fun, but I do it for me. So donations are welcome, but I will not invest any time in it.
Option 4 - Unsigned Software (reluctant choice)
The solution I will be going for, for now. I will create distributions so users can use it easily if they want to, but they do have to perform an extra step to make it work. I hate this is what it is, but I refuse to pay a yearly fee to write free stuff. I really hope Apple finds a way to change this policy. So unless I get donations of more than $99,= a year, I will be doing it this way for now…
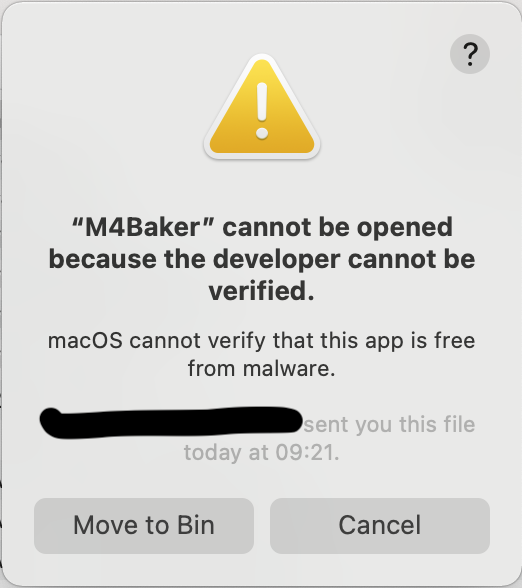
Open “Unidentified Developer” Apps On Your Mac
The example I give here is for my M4Baker.app, but the procedure is the same for any unsigned software. Be careful what you install and do your research before doing it and scan all your downloads with a virus scanner and stuff, but don’t dismiss freeware just because it is not signed.
The installation process will not give any problems as that has nothing to do with signed software.
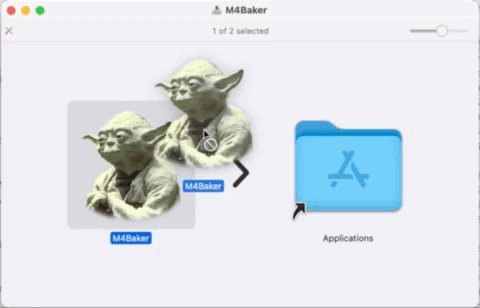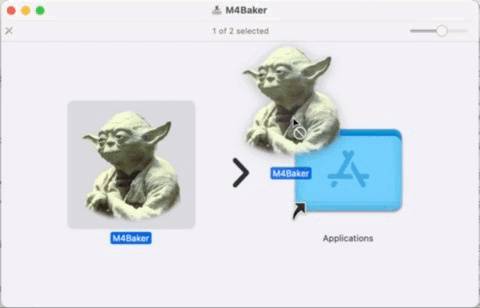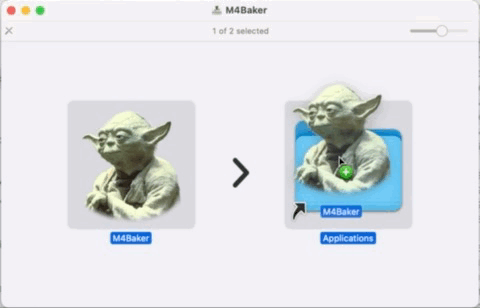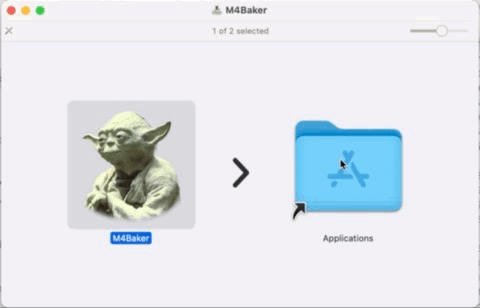
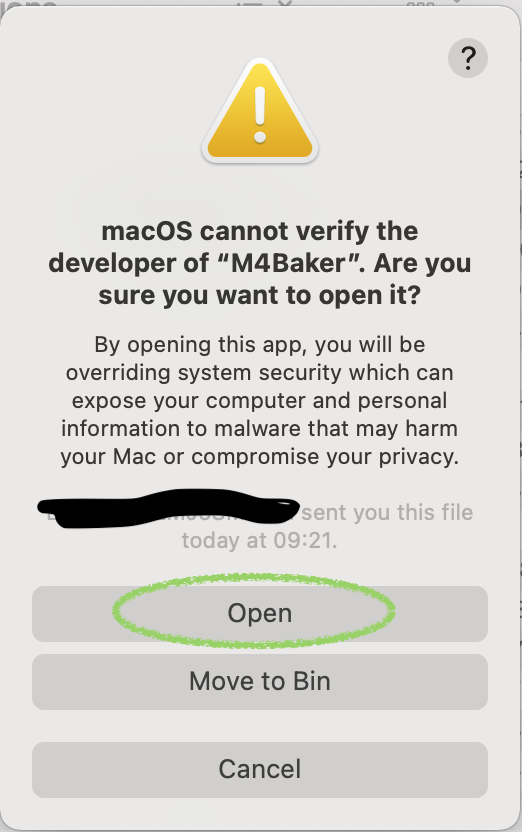
Once you have downloaded the distribution (M4Baker_x.x.x.dmg) and installed it, you try to open it and get a message like the one at the beginning of this article. Choose Cancel at this point.
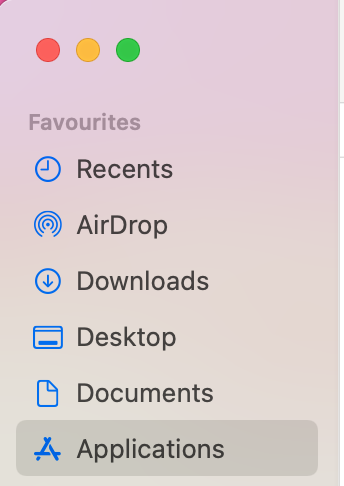
Open a Finder and navigate to the Applications folder.
in Finder either go to the Applications folder as shown above or press command+shift+A or through the menu > Go > Applications
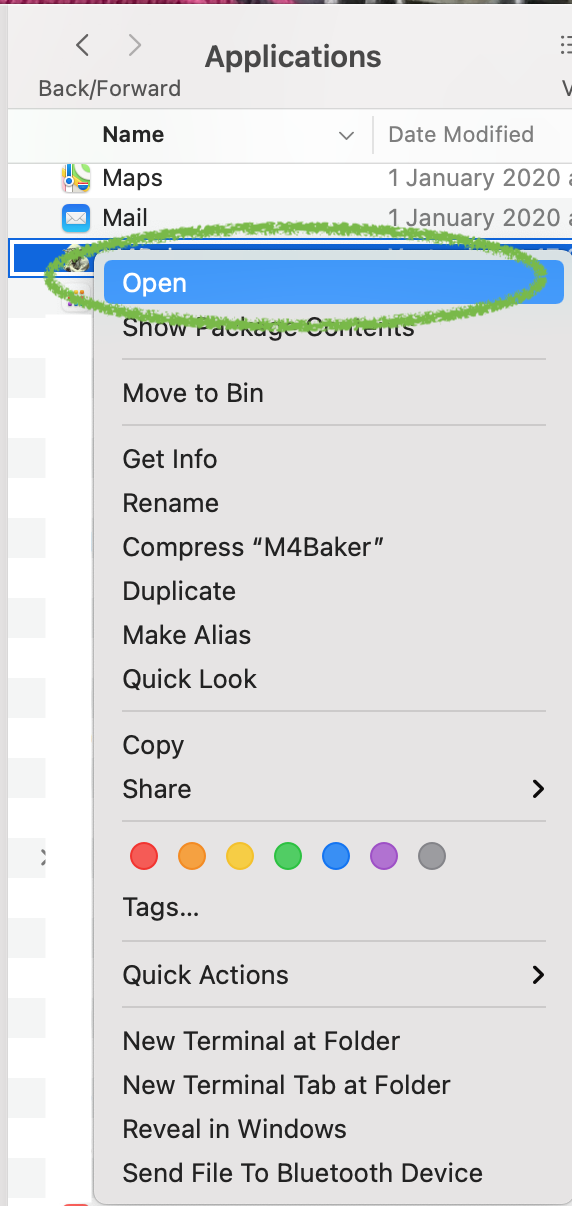
Scroll to your freshly installed app (M4Baker.app) and right click with your mouse on it.
Choose the Open option…
Now the application wil start normally
You only have to do this once for a version, so the next time you can start the application the “normal” way like you are used to.
None of the above
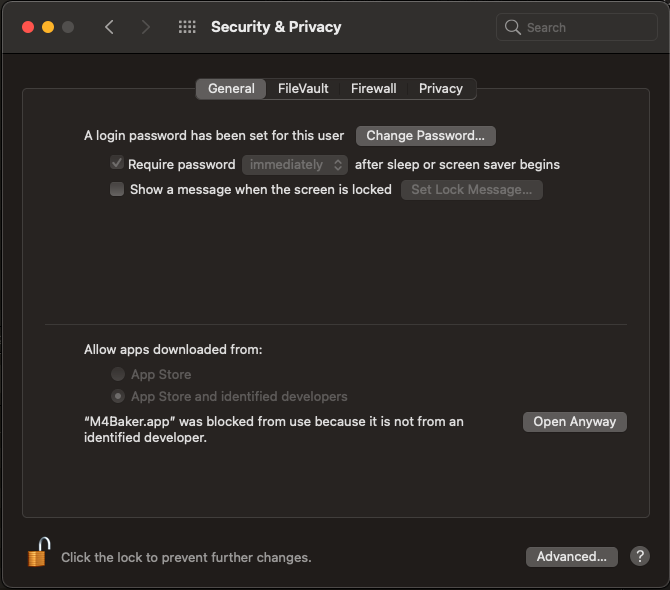
If the above description does not work you can also enable it through the System Settings:
and if you know what you are doing, you can also type the following in the terminal to enable opening Unsigned software:
1
sudo spctl --master-disable
Conclusion
I find it difficult to accept that I can not distribute my creations for free any more in this day and age.
Words like unsigned / unidentified in combination with security makes me feel ‘dirty’ and ‘untrustworthy’ while I am neither. I don’t like the feeling.
I will distribute my software only through my own site. If you download my creations through anything other than “*.ivonet.nl” or site(s) I specifically name (e.g. my github space) I would say they are really unsigned and unidentified and not to be trusted. If downloaded through my site it comes from me, and I have built it 😄 (unless I was hacked, which I hope will never happen).
I do not write malware and if that ever is found in my creations I will be just as much a victim as you are!
All the other disclaimers / licenses and stuff still apply of course! I am a creator and not infallible!
I hope you enjoy some of my creations and don’t hesitate to leave comments or post a tweet @ivonet
Cheerz,
Ivo.
]]>
<p><img src="/images/2021/open-unidentified-developer-apps-on-your-mac/m4baker_cannot_be_opened.png" style="width:50%;height:50%;display: block;margin: 0 auto;"></p>
<h1 id="Problem"><a href="#Problem" class="headerlink" title="Problem"></a>Problem</h1><p>Writing free software for macOS is <strong>impossible</strong> because a developer (like me) first needs to become part of the<br><a href="https://developer.apple.com/programs/how-it-works/" target="_blank" rel="noopener">“Apple Developer Program”</a> to sign Applications and that costs $99,== a year.</p>
<p>A lot has been said about this subject and some Apple fanboys/girls will say that this is a sensible way for Apple to control software quality.<br>To some extent I would even agree as a valid certificate shows that your software hasn’t been tampered with and,<br>if it turns out to be malware, Apple can revoke your certificate. </p>
<p>The cynic in me though also sees it as a way to extort $99,= a year<br>for each developer out there. How can I have my creations effectively distributed for fee if I can not sign it for free?<br>That would make it less than free for me and ruin the fun in my hobby projects…</p>
Audible Aax 2 M4B Conversionhttp://www.ivonet.nl/2021/02/09/audible-aax-2-m4b-conversion/2021-02-09T17:59:00.000Z2021-03-05T06:53:51.000Z
I do not like DRM
I do not like DRM. I get it though. If you give away a book (paper) then you do not have it anymore and it stays 1. if you remove the DRM of a digital (audio)book you can give it away and still have your own copy. That is not good for business and is just wrong.
But as I have no intention of fencing my books (get your own!)… I want the DRM gone! I do have some legacy devices I still use and that is a problem. I want to easily listen on all my devices without having special software installed or linking all the accounts to enable the digital rights.
I don’t think I am doing anything wrong, but if you do not feel comfortable using what this article describes… don’t use it :-)
De-DRM aax files
Prerequisites
Docker installed
What will it do
The docker container will:
use ffprobe to find the checksum of the aax file and extract some essential metadata (json)
use rcrack to retrieve the Activation Bytes based on the checksum
use the Activation bytes to convert the aax to m4b with ffmpeg (keeping as much metadata as possible)
use AtomicParsley to put the minimal metadata into the m4b
use ffmpeg to extract the cover
use mp4art to add the cover to the m4b
move the final m4b to the /output volume
Usage
log into your audible account on your pc and download a book/podcast/audiothingy
Put your aax file in a folder and open a terminal there
run the following command replacing file.aax with your file
it should do the rest.
in the first volume is where the aax file must be
the second volume is where the m4b file will be written to.
The use of this tool is completely at your own choice and volition. I do not encourage it. It is for personal use and any misuse is your own responsibly
See also the license on the github page. Just don’t be a dick!
Hopefully this blog will help to keep my (and your) images alive after this Terms of Service change.
Problem
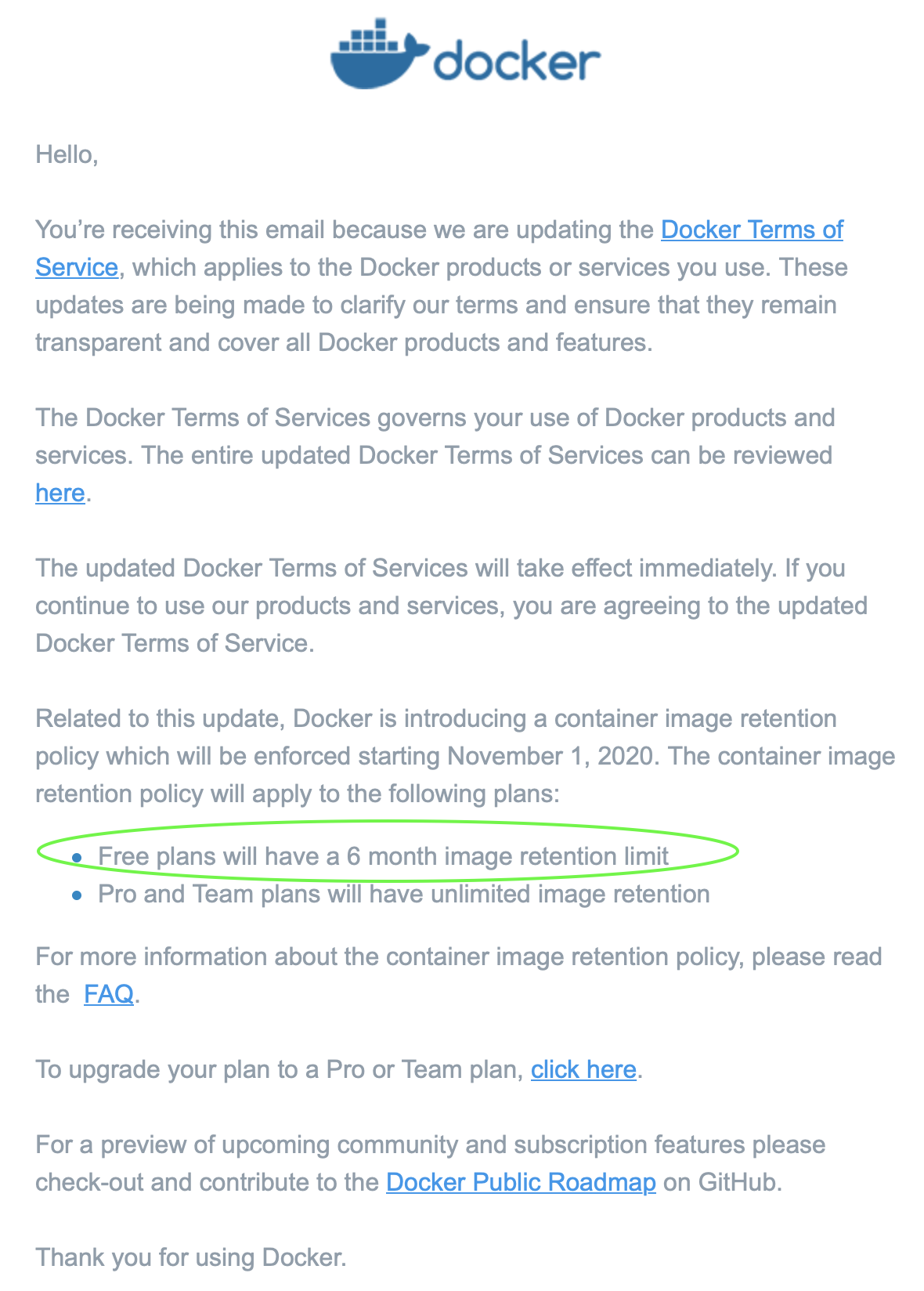
Due to the new Terms of Service inactive images will be removed after 6 month.
On the docker site they explain what inactive means:
What is an “inactive” image? An inactive image is a container image that has not been either pushed or pulled from the Docker Hub image repository in 6 or more months.
This is not an unreasonable thing. Never used images should probably be cleaned.
The problem I have is that I have made some images explicitly created to keep hold of some older stuff like older java versions. Just to be able to run older software. So I want these images to stay even though I do not use them often.
Solution
According to the rule described above I only have to pull the images once in a couple of month to keep them marked as active.
So I need something that can get all the images with the tags I have from the docker hub and refresh them by either pulling them and removing them again or only refreshing them if I already have it locally.
set -e function list_include_item { local list="$1" local item="$2" if [[ $list =~ (^|[[:space:]])"$item"($|[[:space:]]) ]] ; then result=0 else result=1 fi return$result }
echo"Retrieving local images for ${ORG}..." LOCAL_EXISTING_IMAGES=$(docker images --format '{{.Repository}}:{{.Tag}}' | grep "^${ORG}")
echo"Retrieving repository list for ${ORG}..." REPO_LIST=$(curl -s -H "Authorization: JWT ${TOKEN}" https://hub.docker.com/v2/repositories/${ORG}/?page_size=200 | jq -r '.results|.[]|.name')
echo"Refreshing all repositories and tags for: ${ORG}" for i in${REPO_LIST} do IMAGE_TAGS=$(curl -s -H "Authorization: JWT ${TOKEN}" https://hub.docker.com/v2/repositories/${ORG}/${i}/tags/?page_size=300 | jq -r '.results|.[]|.name') for j in${IMAGE_TAGS} do TAG="${ORG}/${i}:${j}" if list_include_item "${LOCAL_EXISTING_IMAGES}""${TAG}"; then echo"Refreshing : ${TAG}" docker pull ${TAG} else echo"Pulling and removing: ${TAG}" docker pull ${TAG} docker rmi ${TAG} fi done done
This small script seems to do the job.
Now I can run this on my NAS or something and even as a scheduled job.
e.g. every 3 month:
1
0 0 1 */3 * /path/to/script/docker-hub-refresh.md
Hope you like it 😄.
Greetz, Ivo.
]]>
<p><img src="/images/2020/docker-hub-refresh/docker-hub-refresh.png" style="width:50%;height:50%;display: block;margin: 0 auto;"></p>
<p>Hopefully this blog will help to keep my (and your) images alive after this Terms of Service change.</p>
Generic Code? Just Don'thttp://www.ivonet.nl/2020/08/17/generic-code-just-dont/2020-08-17T07:35:00.000Z2020-08-26T08:57:46.000Z
Or should I say “Just Don’t Bother”?
A long time during my career writing generic code was the ultimate goal. Invent the wheel only once right? Sounds amazing!
The trouble is that if we look at how we do things these days, one can safely say that we still haven’t figured out how to do this correctly yet…or do we?
This article uses a service with API and endpoints as the example, because services are a very common part of software development. This article is absolutely also applicable to libraries, components and frameworks.
Situation…
So you are writing a generic service. Generic is good, you have heard! It is expected to get many clients in the future. You need to disclose information from your domain. You have analysed your domain and know what de most important information is. You have a good idea on how to do this and have created a nice API and are happy with the results. You tell your first customer, who enabled you to write this service in the first place, how they must use your service. The customer frowns and asks: “Why do I have to filter out this data? I didn’t ask for this data?” You tell the customer that it is a generic service and build for the future. The customer frowns again, but complies as you are both from the same company, and the customer knows they can do this filtering. The customer might even be happy, because they finally got something they can work with. They have to add a new database and configuration to their own client to keep track of the things they have to filter, but the client is able to get the needed data. Then new features need to be build. Your service grows and grows. New customers had questions for your domain you had not anticipated.
To account for more and more specific scenario’s, the API also needs to change often. All the Clients need to filter out data they do not need because they are calling a generic service (generic != specific), and they get way more data than they need. Clients are unhappy and feature creep is happening at a large scale. Now you have to think about how to work with multiple versions of your service in production and about a scenario on how to force your customers to upgrade within a certain amount of time. Soon there is nothing left of your initial beautiful API. At some point it becomes too difficult to work with, due to all the configuration options and edge cases and because clients need to do too much themselves to get to the information, like building their own filters and possibly security.
Then we build a new service to replace the old one because nobody wants to work with it anymore. The new service is amazing. It doesn’t suffer from a bloated API. It works and performs awesome, and it does more or less the same as the other service. Time passes and now the same cycle of development as before is happening and before you know it you are in the same situation again. It too becomes bloated and needs to be replaced with something new. Customers need to change to new versions of the service, or a completely new service, more and more and are not happy.
So if this cycle is happening again and again, what are we doing wrong?
Generic much… too much?
Writing reusable code is a good thing and a good goal. Reusable code needs to be generic to some extent. It is a basic requirement.
An important question to ask though is at what level?
Writing a single, flexible, all encompassing, monolithic service applicable to a whole domain for a broad range of use cases is extremely difficult. It would mean you have to know just about every use case beforehand. Looking into the future is not one of the skills people have at this time. So it is not only difficult it is next to impossible.
A generic service might also seem easy to make for the providing party, as they are exposing everything in their domain, but what is your added value than above your database? Making a service too generic will not make it more usable.
You might say that the more generic something is the less usable it becomes.
That is not all. Being too generic can actually hurt re-usability. Most clients will have to do post processing to extract the actual data they need from a generic service. This makes the client tightly coupled to the service as it needs more knowledge and filtering on the data of the generic service. By being more tightly coupled it is less easy for the client to be moved or reused. So you might say that making a generic service will make working with it more complicated for clients. This can of course result in it not being used at all, which would defeat the purpose.
So if too generic is not the way to go… what then?
One thing…
How do we solve this problem? How to write reusable code? The solution lies in thinking smaller. Write a service which does one thing and one thing well. At the time a service is build you probably have a customer asking for specific information from your domain. That customer is at that time the only reason this service is actually build. You might expect more customers, but you don’t know for sure, and you really don’t know what they might want. Listen to this real and current customer. What does he/she want? specifically! Can I be of value to this customer? How? Can I answer his/her question? Yes! Let’s do that then! Now you are writing a service with immediate and specific value to a customer. You are not looking into the future for a possible need you don’t know about. You know what you are writing is needed.
On component level you can say you are having a single responsibility.
The first principle of the Agile Manifesto says:
Our highest priority is to satisfy the customer through early and continuous delivery of valuable software.
If you ‘are’ agile and not ‘do’ agile (there is a distinction!), you can be happy as you are delivering immediate value. In fact, you will probably have to do way less than you had to do for that generic service. You have a conversation with your customer and know what is asked. You can embrace change during the development and ask for frequent feedback. The result is a small, well written service with clear API and responsibility. It is maintainable and trust is high that it does what the customer wants.
Now a short while later a new customer comes along with a question for your domain. Does it match what your first service already provides? If it does, you are done and if it does not you can have the same conversation again with the new customer. You might write a new service for this specific value. Now you are not reusing code but team knowledge. You have experience in writing a service like this. The service will be written faster but still for a specific customer and with a guaranteed value.
The original service did not need to change at all. The new service is just as simple in design and use, but answers a new use case.
Time goes by and more services have a need to be written. Experience is now very high.
A Way of Working has been established.
You might even have invested in a template, which is a form of reuse many people do not think of. You have a nice set of services, and you now also have more knowledge of you domain and what customers want.
You are looking back to a period of delivering actual value and only value and start to see patterns.
You might want to refactor services to these patterns. You probably do not even have to change the existing API’s. You are learning from looking back and at valuable code, not at a possibly predicted might be, but never will be future needed code.
Let’s call these valuable services Micro Services… Get it 😄?
Conclusion
Talk with the customer you have and make him/her king!
Reuse can be done on many levels. Team Experience is one of them!
Refactor continuously and don’t be afraid to.
]]>
<p><img src="/images/2020/generic-code-just-dont/generic-code-just-dont_1.jpg" style="width:50%;height:50%;display: block;margin: 0 auto;"></p>
<p>Or should I say “Just Don’t Bother”?</p>
<p>A long time during my career writing generic code was the ultimate goal.<br>Invent the wheel only once right?<br>Sounds amazing!</p>
Create Your Own Drillhttp://www.ivonet.nl/2020/08/11/create-your-own-drill/2020-08-11T16:48:00.000Z2020-08-18T14:58:09.000Z
This project started a few month ago and has gone though some major changes and upgrades. I learned a lot…
How it all started
Well I wanted to create my own powerful drill. Don’t ask me for a reason, it is JBIC (just because I can). I have always been curious about how stuff works and being able to (re)create stuff is, to me, a good way to prove that I know how it works.
By creating something you will experience things you van not really get from a book.
It starts with an idea…
The idea
I want to create my own power tool and specifically a cordless drill.
Then you need to decide what you need to get it all to work.
Lists
Batteries 18650. (I already had a bundle of these from old laptops)
circuit board. S6 to protect the batteries against over-charging and over-emptying and balancing the batteries. Li-ion batteries don’t like that much.
Power converter
LED lights
charger
housing for the drill
switch(es)
tools for assembly
DC motor
The list seems easy right? now the real thinking starts.
What do you mean by housing?
charger?
where to get the switches / circuit board(s) etc.
Getting things done
These ideas often float around in my head for a while before I start acting on it. It directs some of my youtube searches for research purposes when I have some spare time. At some point I think I have enough information to start gathering material. I already had some experience with 18650 batteries and their circuits, so I went to ali-express and started ordering stuff.
Now the waiting game starts again. some items arive in a few days some in weeks. So in the meantime what about the housing? First I thought to make it out of wood, but I don’t think I have the tools for it at this time, so what else?
Time to go to a hardware store and just stroll around and let your mind and feet wander around. At the plumbing section I think I hit pay dirt. For this project Aesthetics was not my main goal. I wanted to create a fully functioning tool from just an idea. Practice and evolution is they way to beauty IMHO so let’s first practice and make it work. Plumbing pipes it is.
intermezzo
It is good to realize that I have many of these kinds of projects in my head, and I am not always actively working on them. I have this bullet journal to draw and keep track of these ideas. Sometimes I have no inspiration for months on end or have had to shelve a work in progress idea again because I have to go back to the drawing board. Failed proof of concepts or just having ordered the wrong parts. Actually that last part happens more often than I thought when I started making stuff. Ah well learning by doing. Eventually most of my projects do get done though because it keeps nagging me in the back of my head.
This drill is one of those projects. I have had to shelve it multiple times because I learned something while working on it that would delay the final product.
In this case most of my delay came from that pesky thing called Ampere.
The first protection boards I bought could not handle the load of a 775/785 DC motor or the peak load. I had not taken that into account at all and had to try multiple times and even by specialized tooling to measure these loads to get to the load I needed. Which was way more than I had calculated.
I had measured these DC motors without and they would draw like 1,5-2,5 amps. I had neglected to measure startup load and load when actually having to do something 😄. Kinda a big difference! On peek load it sometimes drew 10+ Amps and none of my circuit boards came even close to handling these kinds of power. So back to the drawing board again.
I had the hardest time finding the push button trigger. I had no idea how it was called and finding something you do not know the name of sometimes hard. Knowing what it had to be but not even able to describe it for searches, well it took a while 😄.
Stuff like that, but in the end small steps forward…
building it
Now slowly but surely assembly could start to happen. I thought I had all the tools I needed and all the parts so…
Battery pack
Power was one of the main things, and I wanted to do it safely. I had seen many youtube movies where the 18650 li-ion batteries would be directly connected to the motor, but all my research tells me that that is a very bad idea, and I do not like bad ideas. It is one the reasons though that I underestimated how much work this would end up to be.
In the end I choose to go for a 40 amps S6 balancing board, so I could deliver 24 volts and quite a bit of umph 😄. The image you see is still of an S4 configuration with double battery per slot. That didn’t deliver enough power though. I am sorry, but I don’t have a picture of the final configuration, but I choose to go for the S6 in single battery mode. It delivers more than enough power and lasts all day with normal use.
Drill part
The drill part came next and was fun to make. Making it all fit, and it is always fun when it actually happens as imagined. It not often does.
final assembly
Now we are actually getting somewhere. Nearing a finished product.
First the handle…
now to a finished product…
Tools used
This complete build has been done with simple tools:
Hand steel saw
Screw drivers
Stanley knife (carving out some holes in the pipes)
Soldering iron (electronics)
Result
In the end I also added a light to illuminate the drill while drilling. I also learned that this drill can’t be used as a screwdriver (not enough tork) so having build in a two-way turning head was something of an overkill 😄
Hope you liked this build.
]]>
<p><img src="/images/2020/create-your-own-drill/drill-with-flower.jpg" style="width:50%;height:50%;display: block;margin: 0 auto;"></p>
<p>This project started a few month ago and has gone though some major changes and upgrades.<br>I learned a lot…</p>
Cucumberhttp://www.ivonet.nl/2020/06/09/cucumber/2020-06-09T10:25:00.000Z2020-06-22T05:39:25.000Z
Cucumber is a very good tool that supports Behaviour Driven Development (BDD). I have been working with Cucumber a lot over the last couple of years and have also made quite a few mistakes.
In this blog I will describe a way of working with Cucumber and Gherkin I think works best. A kind of Best Practice if you will. I am very much aware there are different ways of working with Cucumber and using Gherkin. I also think that the official documentation contradicts itself, making different interpretations very possible…
It has been a learning curve I must admit, and I have seen it done beautifully and very ugly. I have also been part of the ugly versions 😄…
Cucumber / Gherkin
After working with cucumber, lots of discussions with many colleagues and reading about it on the Internet, I think I have found a way of working with Cucumber that works for me and conforms with at least some of the main schools of thought.
Here it goes…
Feature file(s)
The structure of a Scenario in a feature file should be like
Given (0..n) (And/But) (And/But) When (1) Then (1..n) (And/But) (And/But)
Given:
0 or more (N) steps
0 if no special preparation required (which is rare).
N steps if more settings need to be prepared before the “user” arrives at the specific test situation
It contains only setup steps leading up to the actual test. Examples:
open the browser
setting up test data
setting the browser format
navigate to specific page
Filling in fields as preparation to the test moment
When:
1 stap (there can be only one)
The one and only action that leads to the asserts that follow.
Contains only the user action. Examples:
button click
filling in a field/form if that leads to validation action
Time travel
Then:
1 or more (N) steps;
without Then there is no test (a test needs asserts)
Contains only expects and asserts
In general
Do not use technical language anywhere in the feature-file. Use only functional / user language. e.g. do not use terms like modal / service / true / camelCasingStuff / etc.
Talk in specified form. e.g. first person singular or third person but be consequent and consistent. Example:
When I send my credentials
Write in readable language (like a story)
Avoid code in your steps if at all possible (who is going to test the test?). Rather, add more Givens (And/But) than if statements in your steps.
If you are writing more (plumbing) code to keep the tests working than you have actual code you are doing it wrong!
Try to keep the number of steps in the scenario limited.
Avoid using the Background too much. It does not promote readability, and a When step should never be put into the Background.
A step must only do what it describes with no side effects!
Do not name UI elements by name. Not When I press the submit button but When I send my credentials
Step versus Feature files
Step-files
There are 3 different steps in step files:
Initiators
Mutators
Validators
For a flow you need one (1) Initiator followed by possible Mutators and required Validators
In the steps file you can recognise:
Initiators as Given
Mutators as When
Validators as Then
Feature-files
A test is build up according to an Arrange, Act en Assert schema in the feature-file. The Arrange stage can contain an Initiator and multiple Mutators. The Act stage always contains one Mutator. The Assert stage contains only Validators Here it also important to differentiate between the different stages.
In the feature file you can recognise:
the Arrange stage as Given line followed by And and/or But lines
the Act stage as a single When
the Assert stage as Then lines followed by And and/or But lines
Comparison
It is actually kinda sad that the step-file, and the feature-file use the same names (Given/When/Then) for different things. It does therefore not mean that they need to be synchronised!
Discussion
In the official documentation you can find the following description (parts):
Given
[…] The purpose of Given steps is to put the system in a known state before the user (or external system) starts interacting with the system (in the When steps). Avoid talking about user interaction in Given’s. If you were creating use cases, Given’s would be your preconditions. [/…]
But the following about…
When
[…] It’s strongly recommended you only have a single When step per Scenario. If you feel compelled to add more, it’s usually a sign that you should split the scenario up into multiple scenarios. [/…]
After lots of thought and discussion I concluded this to mean that, e.g. filling a form, not always has to be seen as user interaction in every scenario. You can interpret (and I do) this to be following in mock data before the actual test (When). If you explain it like this everything gets its place quite handily, but I am very much aware that this is playing with words and that an equally good explanation can be that a when is needed for every “action”. but that would violate the “avoid using more that one when” admonition.
Good luck finding your own way :-)
Conclusion
My description above is not “The one true way” but experience enhances my conviction that it is a good way of working. Take the time to explore your options with your team and company. The time spent in the beginning is worth it. Write down the reasons for certain choices and review them. Be especially careful with allowing technical language in your feature files. You won’t recover easily from that mistake :-)
If you do not agree of have enhancements please leave them in the comments below…
]]>
<p><img src="/images/2020/cucumber/00 - Cucumber.jpg" style="width: 50%;height: 50%;display: block;margin: 0 auto;" alt="cucumber"></p>
<p>Cucumber is a very good tool that supports Behaviour Driven Development (BDD).<br>I have been working with Cucumber a lot over the last couple of years and have also made quite a few mistakes. </p>
<p>In this blog I will describe a way of working with Cucumber and Gherkin I think works best.<br>A kind of Best Practice if you will. I am very much aware there are different ways of working<br>with Cucumber and using Gherkin. I also think that the official documentation contradicts itself, making<br>different interpretations very possible…</p>
<p>It has been a learning curve I must admit, and I have seen it done beautifully and very ugly. I<br>have also been part of the ugly versions 😄…</p>